Investigating NVIDIA's Jetson AGX: A Look at Xavier and Its Carmel Cores
by Andrei Frumusanu on January 4, 2019 11:00 AM EST- Posted in
- NVIDIA
- SoCs
- Xavier
- Automotive
- Jetson
- Jetson AGX
Machine Inference Performance
The core aspects of the Xavier platform are its machine inferencing performance characteristics. The Volta GPU alongside the DLA core represent significant processing power in a compact and low-power platform.
To demonstrate the machine learning inference prowess of the system, NVIDIA provides the Jetson boards with a slew of software development kits as well as hand-tuned frameworks. The TensorRT framework in particular does a lot of heavy lifting for developers and represents the main API through which the GPU’s Tensor units as well as the DLA will be taken advantage of.
NVIDIA prepared a set of popular ML models for us to test out, and we’d be able to precisely configure the models in terms of how they were run on the platform. All the models running on the GPU and its Tensor core were able to run at either quantized INT8 forms, or in FP16 or FP32 forms. The batch sizes were also configurable, but we’ve kept it simple at just showcasing the results with a batch size of 32 images as NVIDIA claims this is the more representative use-case for autonomous machines.
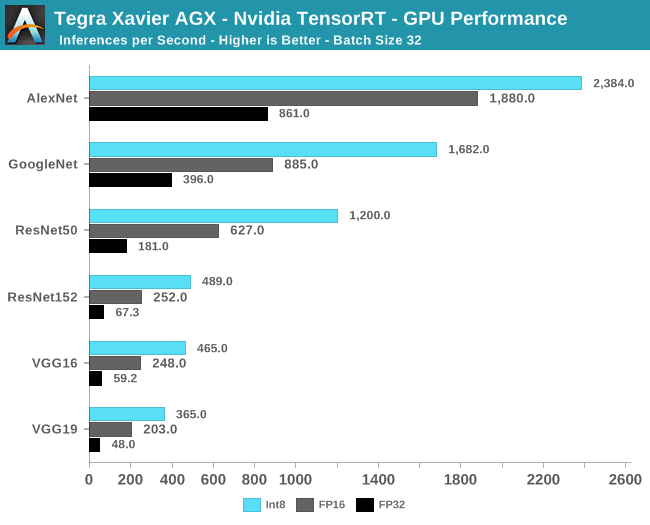
The results of the GPU benchmarks are a bit esoteric because we have few comparison points against which we can evaluate the performance of the AGX. Among the more clear results we see here is that the inferencing performance in absolute terms is reaching rather high rates, particularly in the INT8 and FP16 modes, representing sufficient performance to run a variety of inferencing tasks on a large number of input sets per second. The only real figure we can compare to anything in the mobile market is the VGG16 results compared to the AImark results in our most recent iPhone XS review, where Apple’s new NPU scored a performance of 39 inferences/second.
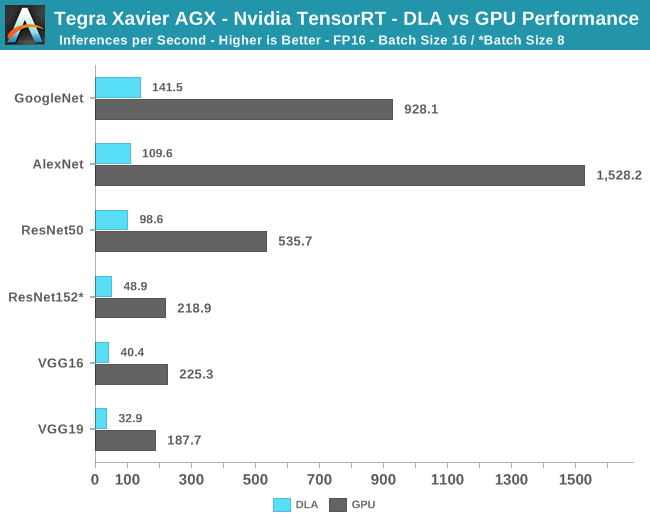
NVIDIA also made it possible to benchmark the DLA blocks, however this came with some caveats: The current version of the TensorRT framework was still a bit immature and thus doesn’t currently allow for running the models in INT8 mode, forcing us to resort to comparisons in FP16 mode. Furthermore I wasn’t able to run the tests with the same large batch size as on the GPU, so I’ve reverted to using smaller sizes of 16 and 8 where appropriate. Smaller batch sizes have more overhead as it takes proportionally longer time on the API side of things and less actual processing time on the hardware.
The performance of the DLA blocks at first glance seems a bit disappointing, as their performance is just a fraction of what the Volta GPU is able to showcase. However raw performance isn’t the main task of the DLA, it serves as a specialized offloading block which is able to operate at higher efficiency points than the GPU. Unfortunately, I wasn’t able to directly measure the power differences between the GPU and the DLA, as introducing my power measurement equipment into the DC power input of the board led to system instabilities, particularly during the current spikes when the benchmarks were launching their workloads. The GPU inference workloads did see the board power reach around ~45W while in its peak performance mode.
NVIDIA's VisionWorks Demos
All the talk about the machine vision and inferencing capabilities of the platform can be something that’s very hard to grasp if you don’t have a more intimate knowledge of the use-cases in the industry. Luckily, NVIDIA’s VisionWorks SDK comes with a slew of example demos and source code projects that one can use as a baseline for one’s commercial applications. Compiling the demos was a breeze as everything was set up for us on the review platform.
Alongside the demo videos, I also opted to showcase the power consumption of the Jetson AGX board. Here we’re measuring the power of the platform at the 19V DC power input with the board at its maximum unlimited performance mode. I had board’s own fan disabled (it can be annoyingly loud) and instead used an externally-powered 120mm bench fan blowing onto the kit. At a baseline power level, the board used ~8.7-9W while sitting idle and actively outputting to a 1080p screen via HDMI while also being connected to Gigabit Ethernet.
The first demo showcases the AGX’s feature tracking capabilities. The input source is a pre-recorded video to facilitate testing. While the video output was limited to 30fps, the algorithm was running in excess of 2-300fps. I did see quite a wide range of jitter in the algorithm fps, although this could be attributed to scheduling noise due to the low duration of the workload while in a limited FPS output mode. In terms of power, we see total system consumption hover around 14W, representing an active power increase of 5W above idle.
The second demo is an application of a Hough transform filter which serves as a feature extraction algorithm for further image analysis. Similarly to the first demo, the algorithm can run at a very high framerate on a single stream, but usually we’d expect a real use-case to use multiple input streams. Power consumption again is in the 14W range for the platform with an average active power of ~4.5W.
The motion estimation demo determines motion vectors of moving objects in a stream, a relatively straightforward use-case in automotive applications.
The fourth VisionWorks demo is the computational implementation of EIS (Electronic image stabilisation), were given an input video stream the system will crop out margins of the frame and use this space as the stabilisation window in which the resulting output stream will be able to elastically bounce against, reducing smaller juddery motions.
Finally, the most impressive demo which NVIDIA provided was the “DeepStream” demo. Here we see a total of 25 720p video input streams played back all simultaneously all while the system is performing basic object detection in every single one of them. This workload represented a much more realistic heavy use-case being able to take advantage of the processing power of the AGX module. As you might expect, power consumption of the board also rose dramatically, averaging around 40W (31W active work).








51 Comments
View All Comments
syxbit - Friday, January 4, 2019 - link
I wish Nvidia hadn't abandoned the mobile space. They could have brought some much needed competition :( :(.Despoiler - Friday, January 4, 2019 - link
The only design that was competitive was the one selected by Google for one generation. 4 ARM cores + a 5th core for power management was a huge failure when everyone can do PM within the ARM SOC. It was only cost competitive in other words.syxbit - Friday, January 4, 2019 - link
The Tegra X1 was a great chip when released.The Shield TV still uses it, and it's an excellent (though now old) chip.
Alistair - Friday, January 4, 2019 - link
And that's not a mobile device. Perf/W for Xavier is also really poor vs. the newest Huawei silicon also.BenSkywalker - Friday, January 4, 2019 - link
The Switch is mobile. When the x1 debuted *four* years ago it obliterated the best from Apple, roughly 50%-100% faster on the gpu side. So yes, if we give the other soc manufacturers four years and a four process step advantage, they can edge out Tegra.Qualcomm's lawyers should take a bow on nVidia not being still present in the mobile market, certainly not the laughable "competition" they had on the technology side.
"Having a hard time seeing a path forward"... That was a cringe worthy line. Why not benchmark direct x on an iPhone and then say the same about the Ax line? Let's take a deep learning/ai platform and benchmark it using antiquated pc desktop applications and then act like there are fundamental design issues... ?
TheinsanegamerN - Friday, January 4, 2019 - link
The tegra X1 doesnt run anywhere near full speed when the device is not plugged into a power source. The Switch also has a fan. It's pretty easy to "obliterate" the competition when you are using a different form factor. I mean, the core I7 with iris pro 580 GPU obliterates the tegra X1, so the X1 must not be very good right?The X1 was WAY too power hungry to use in anything other then a dedicated gaming device with a dedicated cooling system. When restricted down to tablet TDPs, the X1's performance drops like a lead rock.
So, yeah, maybe with another 4 years nvidia could make the tegra work in a proper laptop. Meanwhile, Apple has ALREADY done that with the A12 SoC, and that works in a passive tablet. Nvidia was never able to make their SoC work in a similar system.
Alistair - Saturday, January 5, 2019 - link
Are you replying to my comment? Xavier is new for 2018 and so is Huawei's Kirin 980. We are talking about Xavier, not X1. And Apple's tablet GPU for 2015 equaled nVidia's in perf. The iPad Pro's A9X equalled the Tegra x1 in GPU performance while surpassing it in CPU performance, and at a lower power draw...Alistair - Saturday, January 5, 2019 - link
I think you were conveniently comparing the 2014 iPad's vs. the 2015 X1, instead of the 2015 iPad Pro vs. the X1.Samus - Saturday, January 5, 2019 - link
^^thisniva - Friday, January 4, 2019 - link
Why are there video ads automatically playing on each one of the Anandtech pages? I know you guys are trying to monetize but you've crossed lines that make it annoying for your users to keep visiting the site.