Analyzing Intel’s Discrete Xe-HPC Graphics Disclosure: Ponte Vecchio, Rambo Cache, and Gelato
by Dr. Ian Cutress on December 24, 2019 9:30 AM ESToneAPI: Intel’s Solution to Software
Having the hardware is all well and good, but the other angle (and perhaps more important angle) is software. Intel is keen to point out that before this new oneAPI initiative, it had over 200+ software angles and projects across the company to do with software development. oneAPI is meant to bring all of those angles and projects under one roof, and provide a single entry point for developers to access whether they are programming for CPU, GPU, AI, or FPGA.

The slogan ‘no transistor left behind’ is going to be an important part of Intel’s ethos here. It’s a nice slogan, even if it does come across as if it is a bit of a gimmick. It should also be noted that this slogan is missing a key word: ‘no Intel transistor left behind’. oneAPI won’t help you as much with non-Intel hardware.
This sounds somewhat too good to be true. There is no way that a single entry point can do all things to all developers, and Intel knows this. The point of oneAPI is more about unifying the software stack such that high-level programmers can do what they do regardless of hardware, and low level programmers that want to target specific hardware and do micro-optimizations at the lowest level can do that too.

Everything for oneAPI is going to be driven through the oneAPI stack. At the bottom of the stack is the hardware, and at the top of the stack is the user workload – in between there are five areas which Intel is going address.

The underlying area that covers the rest is system programming. This includes scheduler management, peer-to-peer communications, device and memory management, but also trace and debug tools. The latter of which will appear in its own context as well.

For direct programming languages, Intel is leaning heavily on its ‘Distributed Parallel C++’ standard, or DPC++. This is going to be the main language that it encourages people to use if they want portable code over all different types of hardware that oneAPI is going to cover. DPC++ is an intrinsic mix of C++ and SYCL, with Intel in charge of where that goes.
But not everyone is going to want to re-write their code in a new programming paradigm. To that end, Intel is also working to build a Fortran with OpenMP compiler, a standard C++ with OpenMP compiler, and a python distribution network that also works with the rest of oneAPI.
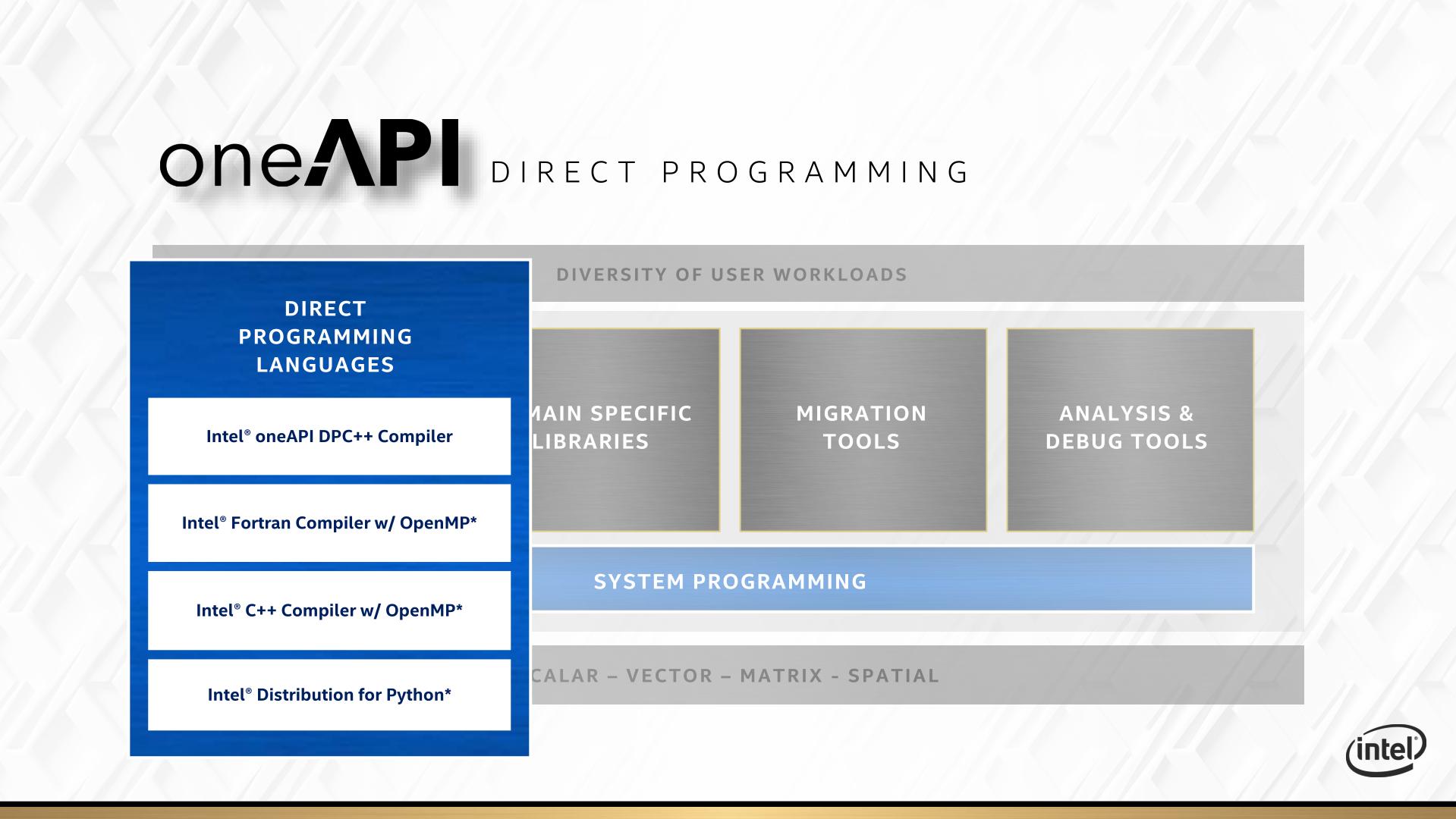
For anyone with a categorically popular workload, Intel is going to direct you to its library of libraries. Most of these users will have heard of before, such as the Intel Math Kernel Library (MKL) or the MPI libraries. What Intel is doing here is refactoring its most popular libraries specifically for oneAPI, so all the hooks needed for hardware targets are present and accounted for. It’s worth noting that these libraries, like their non oneAPI counterparts, are likely to be sold on a licencing model.

One big element to oneAPI is going to be migration tools. Intel has made a big deal what they want to be able to support CUDA translation to Intel hardware. If that sounds familiar, it’s because Raja Koduri already tried to do that with HIP at AMD. The HIP tool works well in some cases, although in almost all instances it still requires adjustment to the code to get something in CUDA to work on AMD. When we asked Raja about what he learned about previous conversion tools and what makes it different for Intel, Raja said that the issue is when code written for a wide vector machine gets moved to a narrower vector machine, which was AMD’s main issue. With Xe, the nature of the variable vector width means that oneAPI shouldn’t have as many issues translating CUDA to Xe in that instance. Time will tell, for obvious reasons. If Intel wants to be big in HPC, that’s the one trick they’ll need to execute on.

The final internal pillar of oneAPI are the analysis and debug tools. Popular products like vTune and Trace Analyzer will be getting the oneAPI overhaul so they can integrate more easily for a variety of hardware and code paths.
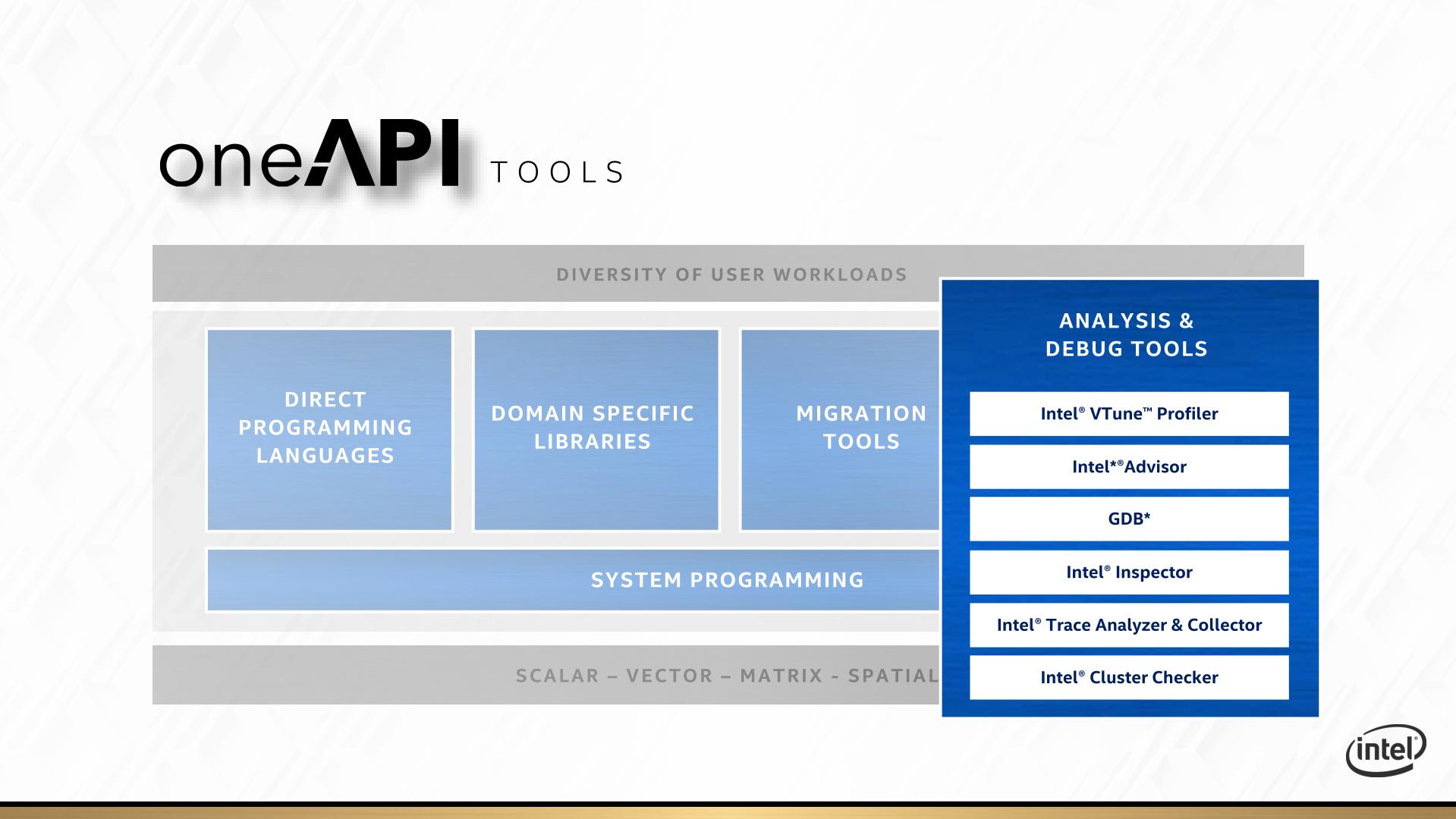
At the Intel HPC Developer Conference, Intel announced that the first version of the public beta is now available. Interested parties can start to use it, and Intel is interested in feedback.

The other angle to Intel’s oneAPI strategy is supporting it with its DevCloud platform. This allows users to have access to oneAPI tools without needing the hardware or installing the software. Intel stated that they aim to provide a wide variety of hardware on DevCloud such that potential users who are interested in specific hardware but are unsure what works best for them will be able to try it out before making a purchasing decision. DevCloud with the oneAPI beta is also now available.








47 Comments
View All Comments
martinw - Tuesday, December 24, 2019 - link
> we’re looking at 66.6 TeraFLOPs per GPU. Current GPUs will do in the region of 14 TF on FP32, so we could assume that Intel is looking at a ~5x increase in per-GPU performance by 2021/2022 for HPC.But HPC ExaFLOPs are traditionally measured using FP64, so that means a ~10x increase.
Santoval - Tuesday, December 24, 2019 - link
If Intel manage to deliver ~67 TFLOPs of *double* precision in a single GPU package -even if it consists of multiple GPU chiplets- I will eat the hat I don't have. ~67 TFLOPs of single precision in a single GPU package might be possible (at a 480 - 500W TDP) due to Intel's new GPU design and its 7nm node, which should be quite more power efficient than their 10nm & 14nm nodes, assuming Intel can fab it at a tolerable yield that is.The use of Foveros and EMIB also reduce the power budget and increase performance further, because they alleviate I/O power draw and, along with that "Rambo cache", mitigate the memory bottleneck. The graphics memory will also probably be HBM3, with quite a higher performance and energy efficiency.
So a ~5x performance at roughly x2 the TDP of the RTX 2080 Ti might be doable. It is ~2.5 times the performance per watt, which is high but not excessive. To double that performance further though is impossible. Intel are a semiconductor company, they are not wizards.
nft76 - Wednesday, December 25, 2019 - link
I'm guessing the number of nodes (and GPUs) will be at least two, probably more like three to four times larger than estimated in the article. I'm guessing that the ~200 racks is without storage included and there will be more nodes per rack. If I'm not mistaken, Cray Shasta high-density racks are much larger than standard.eastcoast_pete - Tuesday, December 24, 2019 - link
Thanks Ian, Happy Holidays to All at AT and here in "Comments"!My first thought was, boy, that lower case/upper case in oneAPI is really necessary; reading the subheading, I almost thought it's about an unusual Irish name (O'NEAPI), w/o the apostrophe.
On a more serious note, this also shows how important the programming ecosystem is; IMO, a key reason why NVIDIA remains the market leader in graphics and HPC.
UltraWide - Tuesday, December 24, 2019 - link
Nvidia recognized this more than 10 years ago, everyone else is playing catch up.JayNor - Tuesday, December 24, 2019 - link
Intel is extending Sycl for FPGA config using data flow pipes. They've mentioned previously that Agilex will have the first implementation of pcie5 and CXL. Perhaps OneAPI will do something to simplify FPGA design.https://github.com/intel/llvm/blob/sycl/sycl/doc/e...
JayNor - Tuesday, December 24, 2019 - link
Intel's current NNP chips don't have PCIE5 or CXL, and I recall some discussion about it being a feature that the NNP-I chips did manual memory management.Is Intel enthusiastically pushing shared memory for the GPU high performance programming, or is this just a convenience during development to get CPU solutions working on GPU quickly?
ksec - Tuesday, December 24, 2019 - link
>The promise with Xe-HPC is a 40x increate in FP64 compute performance.Increase
One or two other spelling mistakes but I can no longer find it.
>The CPUs will be Sapphire Rapids CPUs, Intel’s second generation of 10nm server processors coming after the Ice Lake Xeons
First time I heard SR will be an 10nm++ CPU, always thought it was destined for 7nm. Possibly Another Roadmap shift.
Other than that Great Article. But as with anything Recent Intel, I will believe it when I see it. They are ( intentionally or not ) leaking lots of benchmarks and roadmaps, and lots more "communication" on the ( far ) future as some sort of distraction against AMD.
I have my doubt on their GPU Drivers, not entirely sure their 10nm yield and cost could compete against NV and AMD without lowering margin. But at least in terms of GPGPU it will bring some competition to Nvidia's ridiculously expensive solution.
Alexvrb - Tuesday, December 24, 2019 - link
Yeah they'll probably be more competitive in HPC in the short term. For gaming... we'll see. I suspect they'll get murdered in the short term unless they are really aggressive with pricing. If they go this route most likely they'll do CPU+GPU bundle deals with OEMs to force their way into the "gaming" market.Spunjji - Friday, December 27, 2019 - link
That approach seems highly likely.