AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
The memory subsystem (Linux 64-bit)
Most of the applications of the server and HPC world are well multi-threaded and scale nicely with more cores. With the exception of some rendering engines, this also means that our hard working quad-core CPUs will require quite a bit more bandwidth when they are processing these multi-threaded applications. In our previous review, we found out that:
- Barcelona's L2 cache is 50 to 60% faster
than the older Opteron (22xx). So each core gets at least 50% more L2 bandwidth.
- Each Barcelona's L2 cache is almost as fast as the
shared L2 cache of a similarly clocked 65nm Core based Xeon.
The Intel Xeon has a big advantage of course: its L2 cache is 8 to 12 times larger!
- Barcelona's single-threaded memory bandwidth is 26% to 50% better than the older Opteron and almost twice as good as what a similar Intel Xeon gets.
The problem is of course the word "single-threaded". Those bandwidth numbers are not telling us what we really want to know: how well does the memory subsystem keep up if all cores are processing several heavy threads?
We only had access to the Intel and GCC compilers, and we felt we should use a different compiler to create our multi-threaded stream binary. GCC would probably not create the fastest binary and Intel's compiler might give the Core architecture too many software prefetch hints (or other tricks that might artificially boost the bandwidth numbers). Alf Birger Rustad helped us out and sent us a multi-threaded, 64-bit Linux Stream binary based on v2.4 of Pathscale's C-compiler. We used the following compiler switches:
-Ofast -lm -static -mp
We tested with one, two, and four threads. "Two CPUs" means that we tested with four threads on dual dual-core and eight threads on dual quad-core. "2 CPUs" also means that we used only one CPU in the 1-4 threads setting and we only used a second CPU in the "2 CPUs" setup.
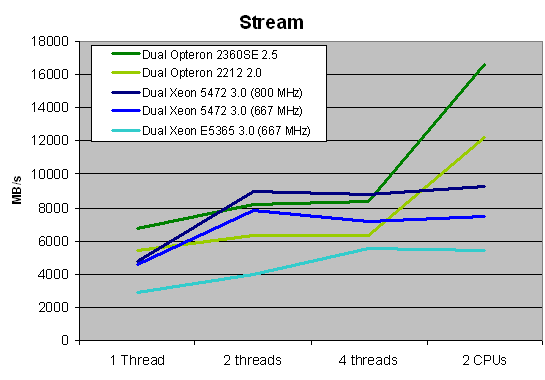
Note that clock speeds do not really matter, except for the Socket-F Opteron. Although we did not include this in the graph above (to avoid color chaos), the clock speed of the socket-F Opteron only matters for the single-threaded bandwidth numbers. Look at the table below:
| AMD vs. AMD Multi-threaded Stream | |||
| 1 Thread | 2 threads | 2 CPUs | |
| Dual Opteron 2212 2.0 | 5474 | 6330 | 12220 |
| Dual Opteron 2222 3.0 | 6336 | 6472 | 12664 |
| Difference 3GHz vs. 2GHz | 16% | 2% | 4% |
| Dual Opteron 23xx | 6710 | 8232 | 16614 |
| Difference Opteron 23xx vs. Opteron 22xx | 23% | 30% | 36% |
With one thread, the 2GHz Opteron 2212 is clearly not fast enough to take advantage of the bandwidth that DDR2-667 can deliver. However, once you make both cores work, this is no longer the case. The Opteron 23xx numbers make clear that the deeper buffers really help: each quad-core has about 30% more bandwidth available than the dual-core. That should be more than enough to keep twice as many cores happy.
The graph above also quantifies the platform superiority that many ascribe to AMD. Likewise, it confirms that the new Intel platform has a much better memory subsystem thanks to the Seaburg chipset. To understand this we calculated the bandwidth numbers, with the "Bensley + Clovertown" platform representing our baseline 100%.
| AMD vs. Intel Multi-threaded Stream | ||||
| 1 Thread | 2 threads | 4 threads | 2 CPUs | |
| Opteron 23xx | 232% | 207% | 150% | 308% |
| Xeon 54xx + Seaburg + 800MHz RAM | 164% | 225% | 158% | 172% |
| Xeon 54xx + Seaburg + 667MHz RAM | 159% | 196% | 128% | 138% |
If you use two CPUs, the Opteron 23xx has no less than 3 times the amount of bandwidth compared to the "old" 65nm Xeon. However, it is much less likely that bandwidth will be a bottleneck for the "new" Xeon 45nm as it has 40% to 60% more bandwidth (with the same kind of memory) compared to the "old" Xeon. If necessary, you'll be able to use 800MHz FBDIMMs that will offer more bandwidth (9GB/s versus 7.7GB/s).
It becomes clear why even a 3GHz Xeon 5365 is not able to beat AMD in SPECFP2006rate: running eight instances of SPECFP2006 is bandwidth limited.
The memory subsystem, latency
To understand the memory subsystem of the different CPUs, we also need to look at latency. We have noticed that many latency measurement benchmarks are inaccurate when you have two CPUs running, so we tested with only one socket filled. Below you can see the numbers for a stride of 128 Bytes, measured with the CPU-Z 1.41 latency test.
| CPU-Z Memory Latency | |||||
| Data size (kB) | Opteron 2212 2.0 | Opteron 2350 | Opteron 2360SE | Dual Xeon
5472 (DDR2-667) |
Xeon E5365 |
| 4 | 3 | 3 | 3 | 3 | 3 |
| 8 | 3 | 3 | 3 | 3 | 3 |
| 16 | 3 | 3 | 3 | 3 | 3 |
| 32 | 3 | 3 | 3 | 3 | 3 |
| 64 | 3 | 3 | 3 | 15 | 14 |
| 128 | 12 | 15 | 15 | 15 | 14 |
| 256 | 12 | 15 | 15 | 15 | 14 |
| 512 | 12 | 15 | 15 | 15 | 14 |
| 1024 | 12 | 44 | 48 | 15 | 14 |
| 2048 | 114 | 44 | 48 | 15 | 14 |
| 4096 | 117 | 111 | 121 | 15 | 14 |
| 8192 | 117 | 113 | 126 | 242 | 215 |
| 16384 | 117 | 113 | 125 | 344 | 282 |
| 32768 | 117 | 113 | 126 | 344 | 282 |
The quad-core Opteron had to make a compromise or two. As the 463 million transistor chip is already 285 mm² in size, each core only gets a 512 KB L2 cache. That means that in some situations (>512 KB) the old 90nm Opteron 22xx is better off as it has access to a very fast 12 cycle L2 cache while the Opteron 23xx has to access a rather slow 44-48 cycle L3 cache.
Note also that the 2.5GHz Opteron 2360 "sees" a slower L3 cache than the 2350: 48 cycles versus 44. The memory controller seems to be ok: the slightly higher latency compared to the Opteron 22xx series is a result of the fact that the Opteron 23xx cores have to check the L3 cache tags, while the Opteron 22xx doesn't have to do that. Notice that memory latency of the on-die memory controller is still far better (+/- 60 ns) than what the Seaburg or Blackford chipset (+/- 70-90 ns) can offer to the Xeon Cores. We have encountered situations where Barcelona's memory controller accesses the memory with much higher latencies (86 ns and more) than the Opteron 22xx but we have to study this in more detail to understand whether this has a realworld impact or not.
Native quad-core versus dual dual-core, part 2
Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
We noticed that running our Cache2Cache benchmark (see here and here) gives results that are more accurate if you measure the results on the same die with only one CPU, and then measure the results from one CPU die to another one with two CPUs. Cache2cache quantifies the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache.
| Cache coherency ping-pong (ns) | |||
| Same die, same package |
Different die, same package |
Different die, different socket |
|
| Opteron 2350 - Stepping B1 | 127 | N/A | 199 |
| Opteron 2360SE - Stepping B2 | 107 | N/A | 199 |
| Xeon E5472 3.0 | 53 | 150 | 237 |
| Xeon E5365 3.0 | 53 | 150 | 237 |
The Xeon syncs very quickly via its shared L2 cache (26.5 ns), but a bit slower from the first CPU to the third one (75 ns). AMD's native quad-core design is a bit faster in the latter case (53.5 ns with the 2360 SE). The difference is slightly less when you have to sync between two sockets (99.5 ns versus 118.5).








43 Comments
View All Comments
Regs - Tuesday, November 27, 2007 - link
I would not expect any from vendors and wholesalers until early next year.Matter of fact I wouldn't want one until then anyhow. I would at least wait until B3 stepping.
TA152H - Tuesday, November 27, 2007 - link
Johan,From my understanding, x87 is now obsolete and not even supported in x86-64. Can you verify this? I know I had read it, from your article you state that Intel improved it, so I'm not as sure. I had assumed one of AMD's handicaps was the disproportionate, and nearly useless, x87 processing power their processors carried, but now I am not as sure. Is x87 supported in x86-64, and if not, why would Intel increase their x87 capabilities when it's clearly a deprecated technology?
JohanAnandtech - Tuesday, November 27, 2007 - link
The x87 instructions can be used in legacy mode and long mode. But it is true that Scalar SSE instructions are preferred by AMD and Intel.x87 performance as many 32 bit programs are still important (look at 3DSMAx 32 bit).
If Intel's newest Core architecture would not have improved the x87 FP it would probably have looked silly as so many 32 bit programs still use it intensively. Secondly, as you can see, things like the Radix-16 circuitry are used by both the SIMD as the x87 units.
Gholam - Tuesday, November 27, 2007 - link
Do you have any plans to benchmark Opteron vs Xeon in an ESX Server environment?DeepThought86 - Tuesday, November 27, 2007 - link
This is exactly what I was thinking of too. I want to change my mode of working to run several separate VM's, one for programming, one for Office etc and really want to know how Phenom compares to Q6600 for those uses. Well, this article looks at the server versions of those chips but for VMware the performance might be more comparable than, say, SuperPi 1M benchmarks!DeepThought86 - Tuesday, November 27, 2007 - link
I forgot to add, since Phenom would presumably also have the nested table support as Barcelona, how much performance improvement would this yield? I'd love to knowsht - Tuesday, November 27, 2007 - link
I was about to ask the same question after reading the concludingYou may feel for example that using four instances in our SPECjbb test favors AMD too much, but there is no denying that using more virtual machines on fewer physical servers is what is happening in the real world.
Since the CPUs have features that should accelerate virtualization, it would really be interesting to see how they compete there. My only addition to your request would be to add KVM as host as well (and XEN and what not as well if you care, though I really think only KVM is of interest).
JohanAnandtech - Tuesday, November 27, 2007 - link
Indeed, we are working on that. The software that we described here (http://www.anandtech.com/IT/showdoc.aspx?i=2997&am...">http://www.anandtech.com/IT/showdoc.aspx?i=2997&am... is being adapted to testing virtualized applications. We are also looking into the parameters that can really influence the results of a benchmark on a virtualized server.JohanAnandtech - Tuesday, November 27, 2007 - link
Indeed, we are working on that. The software that we described here (http://www.anandtech.com/IT/showdoc.aspx?i=2997&am...">http://www.anandtech.com/IT/showdoc.aspx?i=2997&am... is being adapted to testing virtualized applications. We are also looking into the parameters that can really influence the results of a benchmark on a virtualized server.AssBall - Tuesday, November 27, 2007 - link
Thanks, Johan.This has been one of the clearer and better proofread articles I have read here lately. It was interesting, unbiased, and insightful. I am excited to see what you get into for your next project.