Intel Launches Cooper Lake: 3rd Generation Xeon Scalable for 4P/8P Servers
by Dr. Ian Cutress on June 18, 2020 9:00 AM ESTPerformance and Deployments
As part of the discussion points, Intel stated that it has integrated its BF16 support into its usual array of supported frameworks and utilities that it normally defines as ‘Intel DL Boost’. This includes PyTorch, TensorFlow, OneAPI, OpenVino, and ONNX. We had a discussion with Wei Li, who heads up Intel’s AI Software Group at Intel, who confirmed to us that all these libraries have already been updated for use with BF16. For the high level programmers, these libraries will accept FP32 data and do the data conversion automatically to BF16, however the functions will still require an indication to use BF16 over INT8 or something similar.

When speaking with Wei Li, he confirmed that all the major CSPs who have taken delivery of Cooper Lake are already porting workloads onto BF16, and have been for quite some time. That isn’t to say that BF16 is suitable for every workload, but it provides a balance between the accuracy of FP32 and the computational speed of FP16. As noted in the slide above, over FP32, BF16 implementations are achieving up to ~1.9x speedups on both training and inference with Intel’s various CSP customers.
Normally we don’t post too many graphs of first party performance numbers, however I did want to add this one.
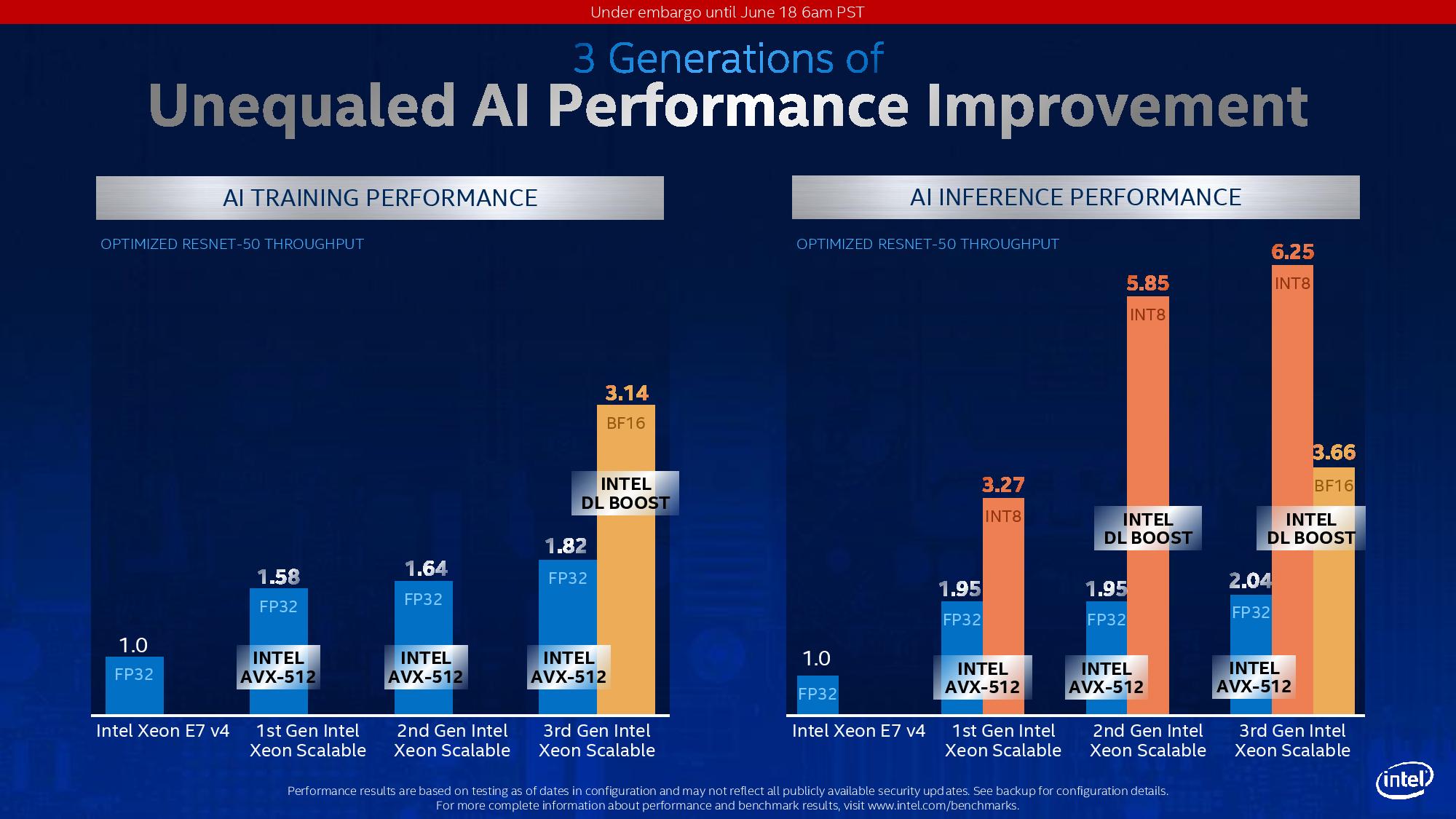
Here we see Intel’s BF16 DL Boost at work for Resnet-50 in both training and inference. Resnet-50 is an old training set at this point, but is still used as a reference point for performance given its limited scope in layers and convolutions. Here Intel is showing a 72% increase in performance with Cooper Lake in BF16 mode vs Cooper Lake in FP32 mode when training the dataset.
Inference is a bit different, because inference can take advantage of lower bit, high bandwidth data casting, such as INT8, INT4, and such. Here we see BF16 still giving 1.8x performance over normal FP32 AVX512, but INT8 has that throughput advantage. This is a balance of speed and accuracy.
It should be noted that this graph also includes software optimizations over time, not only raw performance of the same code across multiple platforms.
I would like to point out the standard FP32 performance generation on generation. For AI Training, Intel is showing a 1.82/1.64 = 11% gain, while for inference we see a 2.04/1.95 = 4.6 % gain in performance generation-on-generation. Given that Cooper uses the same cores underneath as Cascade, this is mostly due to core frequency increases as well as bandwidth increases.
Deployments
A number of companies reached out to us in advance of the launch to tell us about their systems.
Lenovo will be announcing the launch of its ThinkSystem SR860 V2 and SR850 V2 servers with Cooper Lake and Optane DCPMM. The SR860 V2 will support up to four double-wide 300W GPUs in a dual socket configuration.

The fact that Lenovo is offering 2P variants of Cooper Lake is quite puzzling, especially as Intel said these were aimed at 4P systems and up. Hopefully we can get one in for testing.
Also, GIGABYTE is announcing its R292-4S0 and R292-4S1 servers, both quad socket.

One of Intel’s partners stated to us that they were not expecting Cooper Lake to launch so soon – even within the next quarter. As a result, they were caught off guard and had to scramble to get materials for this announcement. It would appear that Intel had a need to pull in this announcement to now, perhaps because one of the major CSPs is ready to announce.








99 Comments
View All Comments
Spunjji - Friday, June 19, 2020 - link
It's the same line every time. It's like listening to a realtor trying to sell a house on a cliff-side."Lovely ocean views, hasn't fallen into the sea any time in the past 20 years, so why would you ever expect it to?"
It also sets up the weird false dichotomy that Intel can't be executing poorly if they're still selling lots of their products; as if the global CPU market would just go away tomorrow just because Intel were selling junk.
Deicidium369 - Saturday, June 20, 2020 - link
Yeah - revenues and profits are never used to measure a business. It's about fee fees and the # of rabid AMD supporters...Sorry that Intel consistently provides what the market wants, and make record revenue quarter after quarter - and AMD Epycs are sitting in systems at the OEMs - since no one is buying them
schujj07 - Saturday, June 20, 2020 - link
Just because someone makes profit doesn't mean it makes what the market wants. Sometimes there is only one option so by design you will make a profit. Doesn't mean that just because you are the only player that your product is what people want. More often than not the product does an OK job but people want something different. In IT data centers the people making the decisions are often times older or just don't know any better. Not to mention when trying to come into a market in which 1 player has >=95% of the mark share it will take time to make inroads.Spunjji - Friday, June 19, 2020 - link
Threadripper isn't a competitor for this product.Duncan Macdonald - Thursday, June 18, 2020 - link
What low price 4S Xeon ? A 16 core 4 socket 4.5TB Xeon (the 6328HL) has a list price of $4779so 4 of these gives a list price of over $19,000 - for comparison a single 7702P costs $4600 and has the same 64 cores as the 4 Xeon CPUs put together and a maximum memory of 4TB (and for good measure has 128 PCIe 4 lanes vs 20 PCIe lanes per Xeon CPU). By the time that you include the price of the required extras for a 4 socket system (4 socket motherboard, special power supplies etc) the 4S Intel system is far more costly than the single socket AMD system.
flgt - Thursday, June 18, 2020 - link
Unless you're a FB or Intel employee, no one has any idea what the real price they pay for these processors. And only AMD and Intel know the margins that can be sacrificed to secure a crucial design win. You also have to balance the manufacturing capacity that can be brought to the table at a given price point. That's a huge advantage for Intel even with all the bad press their manufacturing has received. They can choose to pull capacity from low margin retail products if needed. AMD would have to negotiate with TSMC and compete against their other critical clients for capacity.Spunjji - Friday, June 19, 2020 - link
Technically AMD can also choose to pull capacity from their desktop processor sales if needs be, but you're right that the overall constraints on their manufacturing capacity are more severe.Spunjji - Friday, June 19, 2020 - link
Also worth noting that there's a difference between how much these things cost at list price, how much they cost for a massive organisation buying a few hundred units, and how much they cost for SMEs buying from resellers. I used to work for a large EU reseller and can confirm that even with the customary discounts and bids in place, 4S systems carry a substantial premium over 2S.Deicidium369 - Saturday, June 20, 2020 - link
who cares about some fictional EU retailer you "worked for"...2 socket cost more than a single socket
4 socket cost more than 2 socket
8 socket cost more than 4 socket.
The higher socket count are more expensive per socket than the lower socket count systems - due to the workload and specialized nature of a use case that requires 8 sockets.
Didn't need to work somewhere to know that.
Korguz - Saturday, June 20, 2020 - link
and who cares the BS and FUD that you claim is your own fictional life, but yet, you constantly brad boast and keep making it up as you go along.