Intel Launches Cooper Lake: 3rd Generation Xeon Scalable for 4P/8P Servers
by Dr. Ian Cutress on June 18, 2020 9:00 AM ESTPerformance and Deployments
As part of the discussion points, Intel stated that it has integrated its BF16 support into its usual array of supported frameworks and utilities that it normally defines as ‘Intel DL Boost’. This includes PyTorch, TensorFlow, OneAPI, OpenVino, and ONNX. We had a discussion with Wei Li, who heads up Intel’s AI Software Group at Intel, who confirmed to us that all these libraries have already been updated for use with BF16. For the high level programmers, these libraries will accept FP32 data and do the data conversion automatically to BF16, however the functions will still require an indication to use BF16 over INT8 or something similar.

When speaking with Wei Li, he confirmed that all the major CSPs who have taken delivery of Cooper Lake are already porting workloads onto BF16, and have been for quite some time. That isn’t to say that BF16 is suitable for every workload, but it provides a balance between the accuracy of FP32 and the computational speed of FP16. As noted in the slide above, over FP32, BF16 implementations are achieving up to ~1.9x speedups on both training and inference with Intel’s various CSP customers.
Normally we don’t post too many graphs of first party performance numbers, however I did want to add this one.
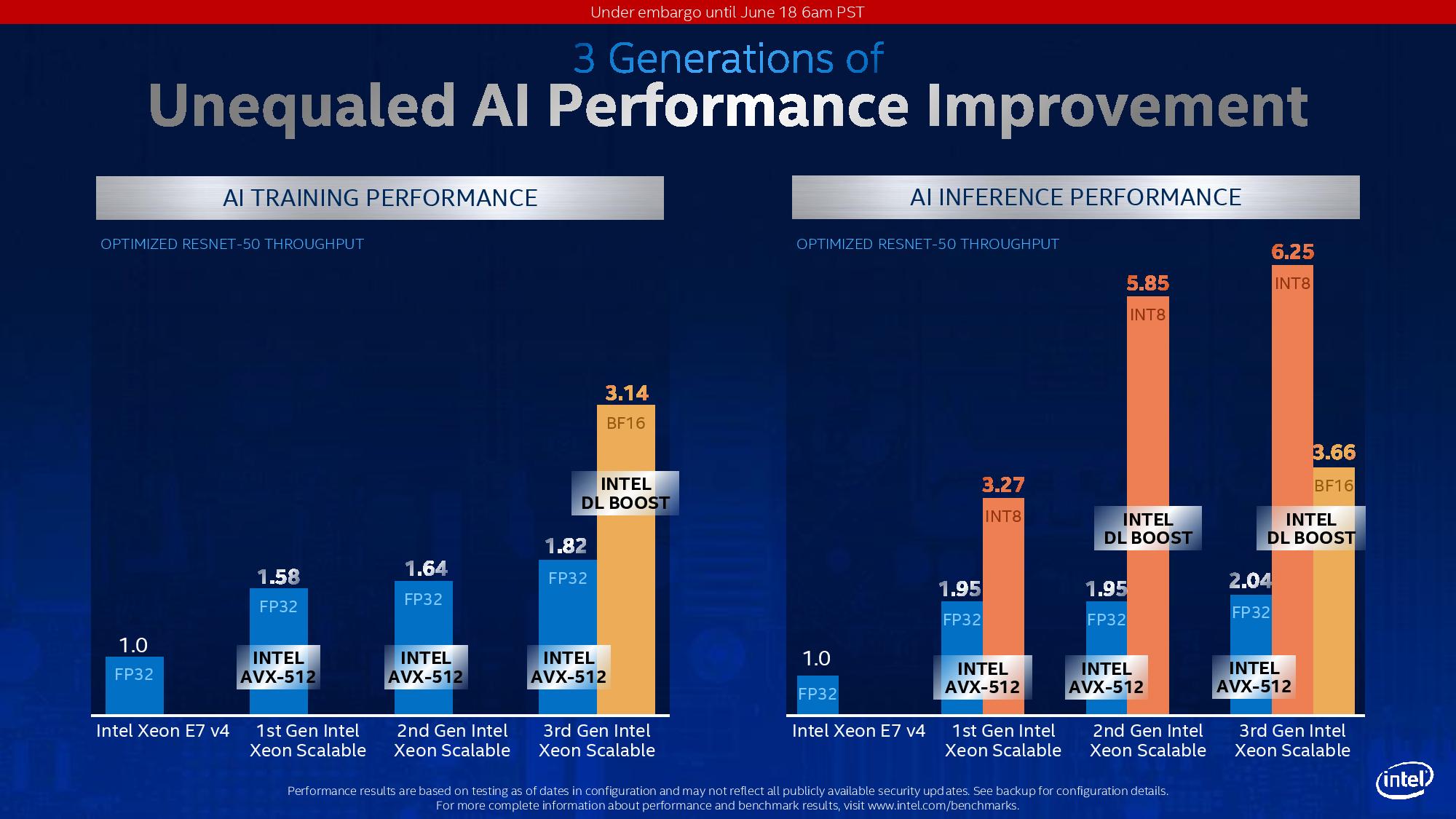
Here we see Intel’s BF16 DL Boost at work for Resnet-50 in both training and inference. Resnet-50 is an old training set at this point, but is still used as a reference point for performance given its limited scope in layers and convolutions. Here Intel is showing a 72% increase in performance with Cooper Lake in BF16 mode vs Cooper Lake in FP32 mode when training the dataset.
Inference is a bit different, because inference can take advantage of lower bit, high bandwidth data casting, such as INT8, INT4, and such. Here we see BF16 still giving 1.8x performance over normal FP32 AVX512, but INT8 has that throughput advantage. This is a balance of speed and accuracy.
It should be noted that this graph also includes software optimizations over time, not only raw performance of the same code across multiple platforms.
I would like to point out the standard FP32 performance generation on generation. For AI Training, Intel is showing a 1.82/1.64 = 11% gain, while for inference we see a 2.04/1.95 = 4.6 % gain in performance generation-on-generation. Given that Cooper uses the same cores underneath as Cascade, this is mostly due to core frequency increases as well as bandwidth increases.
Deployments
A number of companies reached out to us in advance of the launch to tell us about their systems.
Lenovo will be announcing the launch of its ThinkSystem SR860 V2 and SR850 V2 servers with Cooper Lake and Optane DCPMM. The SR860 V2 will support up to four double-wide 300W GPUs in a dual socket configuration.

The fact that Lenovo is offering 2P variants of Cooper Lake is quite puzzling, especially as Intel said these were aimed at 4P systems and up. Hopefully we can get one in for testing.
Also, GIGABYTE is announcing its R292-4S0 and R292-4S1 servers, both quad socket.

One of Intel’s partners stated to us that they were not expecting Cooper Lake to launch so soon – even within the next quarter. As a result, they were caught off guard and had to scramble to get materials for this announcement. It would appear that Intel had a need to pull in this announcement to now, perhaps because one of the major CSPs is ready to announce.








99 Comments
View All Comments
JayNor - Thursday, June 18, 2020 - link
Intel 4S and 8S also increase the memory bandwidth vs a 1S solution, since more memory channels per each socket, right?also ... Ice Lake Server will have Sunny Cove
from 12/12/2018 ARS Technica article:
"Both Intel and AMD have shared these limits since 2003. No longer: Sunny Cove extends virtual addresses to 57 meaningful bits (with the top 7 bits again either all zeroes or all ones, copying bit 56), with physical memory addresses of up to 52 bits. To handle this requires a fifth level in the page table. The new limits enable 128PB of virtual address space and 4PB of physical memory."
Deicidium369 - Friday, June 19, 2020 - link
Agreed - 2 dual socket is preferable to 1 quad socket.The comparison should be between the 2 socket Ice Lake SP and not the Cooper Lake 4 and 8 sockets. Ice Lake SP will be 38C per socket, 76 cores and 128 PCIe4 lanes in a dual socket system. Ice Lake's Sunny Cove brings a 20% increase in IPC - so that 76C performs more like a 90 or 91 core Cooper Lake. So 128 AMD cores vs 90 Intel cores - and the same 128 PCIe4 lanes and the same 8 channel memory - and the ability to use Optane DIMMs
Not much of an advantage anymore.
schujj07 - Friday, June 19, 2020 - link
Due to VMware's change in licensing, no one is going to buy a 38c Ice Lake same as no one will buy a 48c Epyc. The only people who might are cloud providers running open source hypervisors. IDK if you know how the licensing changed, but VMware has changed their license to 32c/socket/license. If you are running a 38c Ice Lake you will need 2 licenses for it, same as the 48 or 64c Epyc. The difference is the 64c Epyc at least maximizes the cores/socket requirement.When Ice Lake is released, it won't be competing against Zen2 Epyc, it will be competing against Zen3 Epyc.On the PCIe lane Ice Lake is still at a disadvantage in a dual socket setup. Depending on configuration, Epyc can have 160 PCIe 4.0 lanes for IO and still have 96 lanes for CPU-CPU communication. Even with 96 CPU communication lanes EPYC still provides ~50% more CPU-CPU bandwidth than an Ice Lake with 6 UPI links. In all honesty Ice Lake only has caught up with 1st Gen Epyc on IO but 2nd Gen on IPC.
Deicidium369 - Saturday, June 20, 2020 - link
Intel will sell as many ICL 38 cores as it can produce - I agree that most will be 32C IF they are destined for a VMware farm..Epyc has 128 PCIe4 Lanes PERIOD. in a dual socket Epyc - 64 lanes on EACH CPU is used to communicate with the other CPU. Leaving 128 PCIe4 lanes for IO. and 64 PCIe4 lanes for CPU to CPU communications..
Cool story
schujj07 - Saturday, June 20, 2020 - link
Wrong. There are 2 different dual socket setups possible. The 128 lane IO lane setup and the 160 lane IO setup. https://www.servethehome.com/amd-epyc-7002-series-... In the 128 IO setup there are also 128 lanes for Cpu-CPUDeicidium369 - Saturday, June 20, 2020 - link
There are no 4 socket Epycs.each CPU has 128 PCIe4 lanes - in a 2 socket system, 64 of them are used as CPU to CPU communications - please explain how you can add additional processors and still have PCIe lanes for, you know, IO.
AnGe85 - Thursday, June 18, 2020 - link
As you can already estimate/derive from the provided graph, Epyc does not compete with Xeon's in DL/ML-Tasks, simply because of missing features.A 4S system based on low priced Xeon's should already be enough to outperform a high-end Epyc system with two 7742. AVX-512, VNNI and DLBoost provide a much higher relative performance due to specialization for these types of workloads.
AMD will provide semi custom Zen3-Epyc's for the Frontier with good cause. ;-)
mode_13h - Thursday, June 18, 2020 - link
But, if you really care about deep learning performance, then you wouldn't use a CPU for it. That's why Intel just spent $2B to acquire Habana Labs.Deicidium369 - Thursday, June 18, 2020 - link
Or FPGAs configured as Tensor cores or tensor coresmode_13h - Thursday, June 18, 2020 - link
Also, AVX-512 has significant performance pitfalls. It's close to being an anti-feature.