Intel Launches Cooper Lake: 3rd Generation Xeon Scalable for 4P/8P Servers
by Dr. Ian Cutress on June 18, 2020 9:00 AM ESTPerformance and Deployments
As part of the discussion points, Intel stated that it has integrated its BF16 support into its usual array of supported frameworks and utilities that it normally defines as ‘Intel DL Boost’. This includes PyTorch, TensorFlow, OneAPI, OpenVino, and ONNX. We had a discussion with Wei Li, who heads up Intel’s AI Software Group at Intel, who confirmed to us that all these libraries have already been updated for use with BF16. For the high level programmers, these libraries will accept FP32 data and do the data conversion automatically to BF16, however the functions will still require an indication to use BF16 over INT8 or something similar.

When speaking with Wei Li, he confirmed that all the major CSPs who have taken delivery of Cooper Lake are already porting workloads onto BF16, and have been for quite some time. That isn’t to say that BF16 is suitable for every workload, but it provides a balance between the accuracy of FP32 and the computational speed of FP16. As noted in the slide above, over FP32, BF16 implementations are achieving up to ~1.9x speedups on both training and inference with Intel’s various CSP customers.
Normally we don’t post too many graphs of first party performance numbers, however I did want to add this one.
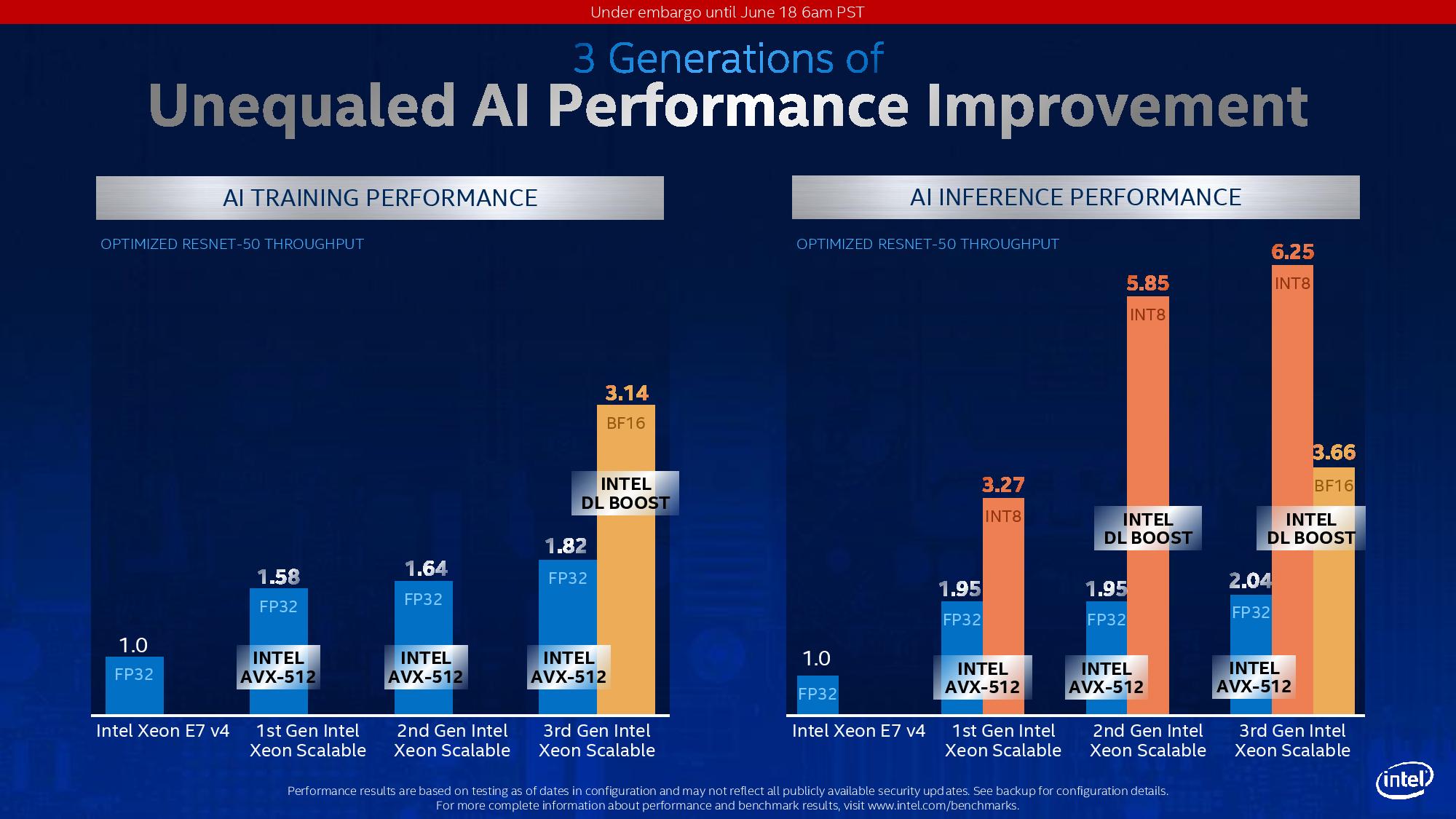
Here we see Intel’s BF16 DL Boost at work for Resnet-50 in both training and inference. Resnet-50 is an old training set at this point, but is still used as a reference point for performance given its limited scope in layers and convolutions. Here Intel is showing a 72% increase in performance with Cooper Lake in BF16 mode vs Cooper Lake in FP32 mode when training the dataset.
Inference is a bit different, because inference can take advantage of lower bit, high bandwidth data casting, such as INT8, INT4, and such. Here we see BF16 still giving 1.8x performance over normal FP32 AVX512, but INT8 has that throughput advantage. This is a balance of speed and accuracy.
It should be noted that this graph also includes software optimizations over time, not only raw performance of the same code across multiple platforms.
I would like to point out the standard FP32 performance generation on generation. For AI Training, Intel is showing a 1.82/1.64 = 11% gain, while for inference we see a 2.04/1.95 = 4.6 % gain in performance generation-on-generation. Given that Cooper uses the same cores underneath as Cascade, this is mostly due to core frequency increases as well as bandwidth increases.
Deployments
A number of companies reached out to us in advance of the launch to tell us about their systems.
Lenovo will be announcing the launch of its ThinkSystem SR860 V2 and SR850 V2 servers with Cooper Lake and Optane DCPMM. The SR860 V2 will support up to four double-wide 300W GPUs in a dual socket configuration.

The fact that Lenovo is offering 2P variants of Cooper Lake is quite puzzling, especially as Intel said these were aimed at 4P systems and up. Hopefully we can get one in for testing.
Also, GIGABYTE is announcing its R292-4S0 and R292-4S1 servers, both quad socket.

One of Intel’s partners stated to us that they were not expecting Cooper Lake to launch so soon – even within the next quarter. As a result, they were caught off guard and had to scramble to get materials for this announcement. It would appear that Intel had a need to pull in this announcement to now, perhaps because one of the major CSPs is ready to announce.








99 Comments
View All Comments
azfacea - Thursday, June 18, 2020 - link
are u suggesting these will compete with IBM z platform or something else on reliability? clearly this is not a reliability play. its commodity x86. and if max core count and max memory and max IO of 8s server does not beat a 4s EPYC, not sure what the selling point is, never mind charging a premium.unless there is particular order from like facebook for BFloat16 its not going anywhere. with a 2x perf disadvantage even that wont be enof for long.
SarahKerrigan - Thursday, June 18, 2020 - link
Not on reliability, just on scalability. 4s/8s x86 is largely replacing RISC/UNIX (*not* z, which is a separate animal.)As for 4s Epyc... you realize that Epyc only goes to 2s, right? If you want a really big tightly-bound x86 system, whether to replace RISC/UNIX or just because you have an interconnect-sensitive app that eats a lot of RAM, Intel goes higher than AMD. That's not a value judgment, it's a statement of fact. That's also an incredibly niche market and always has been - but it's one with good margins, which presumably is why Intel still bothers.
kc77 - Thursday, June 18, 2020 - link
No Eypc can scale further than that. Second, these chips top out at 28 cores. AMD is at a double density advantage (Actually it's worse) . Hell you have to go to 8S on these parts just to beat out the 2S AMD counter parts. The power and density lost is crazy. These are super niche parts. Aside from FaceBook I don't see anyone else getting these.Deicidium369 - Thursday, June 18, 2020 - link
And it seems to the people making the decisions about what goes into the Datacenter - AMD supposed "advantages" are meaningless. The 4 and 8 socket Cooper Lake is destined for hyperscalers.Zibi - Thursday, June 18, 2020 - link
Like Facebook OCP Delta Lake Cooper Lake perhaps ?Too bad it's 2S xD
Deicidium369 - Friday, June 19, 2020 - link
Cooper Lake is 4 and 8 sockets - designed for AI / Hyper scalersIce Lake SP is single and dual socket 38C and 64 PCIe4 lanes per socket.
Deicidium369 - Friday, June 19, 2020 - link
Ice Lake SP has 76 cores and offers 128 lanes of PCIe4 in a dual socket system - this is the mainstream platform - most servers in traditional data centers are 2 socket... makes for an efficient VM farm - better to have 2 dual socket than a single 4 socket. And with the significant IPC increase the Sunny Cove brought (~20%) makes the 76 cores in a dual socket config equivalent to 90 or 91 cores when compared to Skylake derived Comet and Cooper and by extension Epyc. So Epyc may have 128 cores in a dual socket config - that really is not a huge advantage anymore - and with the same # of PCIe4 lanes.. Epyc shows little advantage here.You would be hard pressed to find any motherboard that supports more the 2 Epyc CPUs. there is a poster on Reddit Optilasgar that explains why more than 2 sockets on Epyc are basically not possible
https://www.reddit.com/r/Amd/comments/6jogw9/are_t...
Yeah the 4/8 socket will go mostly to the hyper scalers - Facebook was one of the driving factors for Cooper Lake at 4 or 8 sockets - but you can bet they won't be the only hyper scalers getting them.
Apparently what you see as AMDs advantage isn't what the large customers - hyper scalers or traditional data centers want - revenue show that to be true.
Spunjji - Friday, June 19, 2020 - link
@Deicidum"the significant IPC increase the Sunny Cove brought (~20%) makes the 76 cores in a dual socket config equivalent to 90 or 91 cores when compared to Skylake derived Comet and Cooper and by extension Epyc."
What's this "by extension Epyc" nonsense? Everybody knows Epyc has better IPC than Skylake.
We don't know the clock speeds for Ice Lake SP either, but if it ends up anything like the mobile variants then the IPC increase will be eaten by the clock speed decrease.
Deicidium369 - Saturday, June 20, 2020 - link
Yeah server variants with 270W are going to have the same clocks as the 15W mobile variant,,,you are really grasping at straws. AMD Epyc are roughly comparable to Skylake derived cores - so Comet Lake and Cooper Lake are Skylake derived cores, and Epyc is trying to compete with Skylake - therefore - by extension.. means that Sunny Cove has a 20% IPC advantage over Skylake - which is Comet Lake, Cooper Lake, and AMD Epyc.
mtfbwy - Thursday, June 18, 2020 - link
Then why are the 'rate' numbers for SPEC CPU 2017 Dominated by EPYC? spots #1, #2, and #3 are all EPYC, with socket count of 16, 24, and 32.While the "glue" in this case is software instead of a hardware node-controller, it still makes for a scale-up server; the same technology is also used with Xeons for customers running workloads like SAP HANA - it makes for a far cheaper and more flexible architecture to scale up your memory.