Intel Whittles Down AI Portfolio, Folds Nervana in Favor of Habana
by Ryan Smith on February 3, 2020 10:00 PM EST
Over the past several years, Intel has built up a significant portfolio of AI acceleration technologies. This includes everything from in-house developments like Intel’s DL Boost instructions and upcoming GPUs, to third party acquisitions like Nervana, Movidius, and most recently, Habana labs. With so many different efforts going on it could be argued that Intel was a little too fractured, and it would seem that the company has come to the same conclusion. Revealed quietly on Friday, Intel will be wrapping up its efforts with Nervana’s accelerator technology in order to focus on Habana Labs’ tech.
Originally acquired by Intel in 2016, Nervana was in the process of developing a pair of accelerators for Intel. These included the “Spring Hill” NNP-I inference accelerator, and the “Spring Crest” NNP-T training accelerator. Aimed at different markets, the NNP-I was Intel’s first in-house dedicated inference accelerator, using a mix of Intel Sunny Cove CPU cores and Nervana compute engines. Meanwhile NNP-T would be the bigger beast, a 24 tensor processor chip with over 27 billion transistors.

But, as first broken by Karl Freund of Moore Insights, Spring won’t be arriving after all. As of last Friday, Intel has decided to wrap up their development of Nervana’s processors. Development of NNP-T has been canceled entirely. Meanwhile, as NNP-I is a bit further along and already has customer commitments, that chip will be delivered and supported by Intel for their already committed customers.
In place of their Nervana efforts, Intel will be expanding their efforts on a more recent acquisition: Habana Labs. Picked up by Intel just two months ago, Habana is an independent business unit that has already been working on their own AI processors, Goya and Gaudi. Like Nervana’s designs, these are intended to be high performance processors for inference and training. And with hardware already up and running, Habana has already turned in some interesting results on the first release of the MLPerf inference benchmark.

In a statement issued to CRN, Intel told the site that "Habana product line offers the strong, strategic advantage of a unified, highly-programmable architecture for both inference and training," and that "By moving to a single hardware architecture and software stack for data center AI acceleration, our engineering teams can join forces and focus on delivering more innovation, faster to our customers."
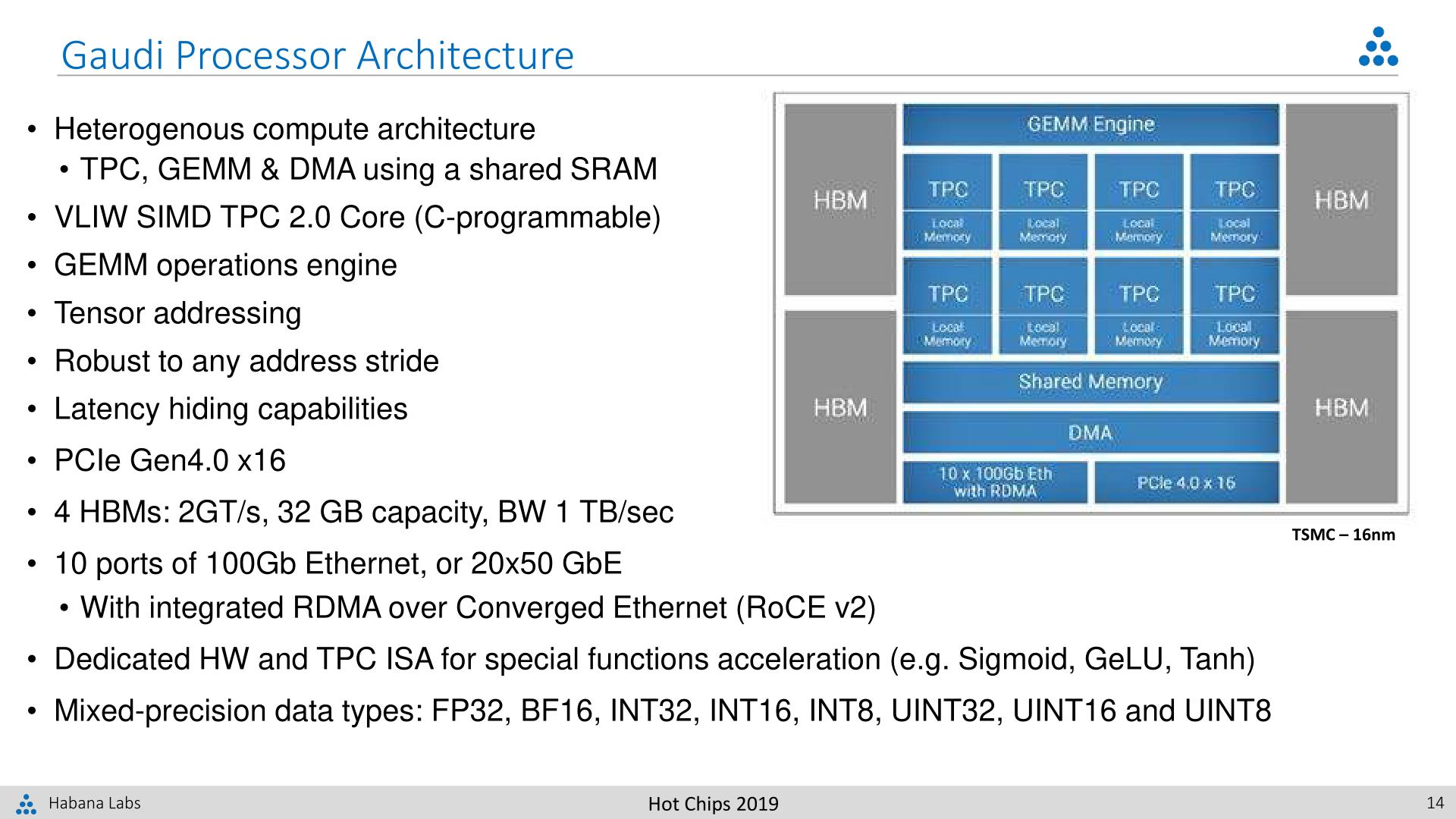
Large companies running multiple, competitive projects to determine a winner is not unheard of, especially for early-generation products. But in Intel’s case this is complicated by the fact that they’ve owned Nervana for a lot longer than they’ve owned Habana. It’s telling, perhaps, that Nervana’s NNP-T accelerator, which had never been delivered, was increasingly looking last-generation with respect to manufacturing: the chip was to be built on TSMC’s 16nm+ process and used 2.4Gbps HBM2 memory at a time when competitors are getting ready to tap TSMC’s 7nm process as well as newer 3.2Gbps HBM2 memory.
According to CRN, analysts have been questioning the fate of Nervana for a while now, especially as the Habana acquisition created a lot of overlap. Ultimately, no matter the order in which things have occurred, Intel has made it clear that it’s going to be Habana and GPU technologies backing their high-end accelerators going forward, rather than Nervana’s tech.
As for what this means for Intel’s other AI projects, this remains to be seen. But as the only other dedicated AI silicon comes out of Intel’s edge-focused Movidius group, it goes without saying that Movidius is focused on a much different market than Habana or the GPU makers of the world that Intel is looking to compete with at the high-end. So even with multiple AI groups still in-house, Intel isn’t necessarily on a path to further consolidation.
Source: Karl Freund (Forbes)








42 Comments
View All Comments
Yojimbo - Monday, February 3, 2020 - link
Habana was just purchased. The correct interpretation is not that Nervana was folded to whittle down a fractured portfolio, but rather that the whole reason Habana was purchased was because of the failure of Nervana.jeremyshaw - Monday, February 3, 2020 - link
The next question is how long will it take before Intel makes a failure of Habana?p1esk - Tuesday, February 4, 2020 - link
Probably as long as it takes Nvidia to ship next gen Tesla cards.10x100GE does look insane though! Anyone has a clue how it could possibly be used?
Yojimbo - Tuesday, February 4, 2020 - link
When training very large models there is a lot of cross-talk. NVIDIA makes fat nodes, but if models need to scale bigger than a few nodes then there is an internode bandwidth limitation. However, it's been a well-known issue for years and something NVIDIA has been working on in their software stack. I have a feeling that one of the key new features of NVIDIA's next generation data center GPUs is better scalability for AI training with large clusters.p1esk - Tuesday, February 4, 2020 - link
How would implement the physical 10x100GE connections? Like bridges? 10 fiber cables? Custom motherboard?Eliadbu - Tuesday, February 4, 2020 - link
There is an implementation for rack with 8 of those accelerators called HLS-1 it's similar to NVIDIA DGX. each accelerators is connected to other accelerator in the node so 7 ports are used for inter node connection and the other 3 ports of each accelerator are routed for connection outside of the node to connect to a switch or different nodes. This is just one implementation, since those cards use common Standard it is really up to the customer to choose how to implement those cards.Yojimbo - Tuesday, February 4, 2020 - link
There are ports coming off the server. I guess the configurators can use fiber or copper or whatever they think is appropriate. According to their website, in the HLS-1 server each Gaudi HL-205 Mezzanine card uses 7 of the 100Gb ethernet connections for in-node communications. Each one has 3 connections to ports coming off the server. So the total ports coming off the node is 24x100Gb. When they expand to multiple nodes in the cluster they use ethernet switches to lash together the nodes through the ethernet connections coming off the nodes. There is no CPU in the server so it needs to be connected somehow to one. I don't know how that connection is made, whether through the PCI express switches or through ethernet. They have a graphic showing 6 HLS-1, 6 CPU servers, and 1 ethernet switch for a full rack.p1esk - Tuesday, February 4, 2020 - link
I wonder what kind of ethernet switch can handle a full rack of servers pumping 2.4Tbps each. I suspect a switch like that costs more than the entire rack.Kevin G - Tuesday, February 4, 2020 - link
Not entirely sure that that is the exact direction nVidia is going.Several nvSwitch ASICs lets upward of 32 GV100's communicate within two hops of each other in a fully coherent fashion as a single node. Per IBM's road map, next generation of nvLink is also around the corner which boosts bandwidth and is a clear indication that Ampere will also support it at the high end.
nVidia did purchase Mellanox so they do have some plans beyond just nvLink for communication but anything integrated from that acquisition is likely years away still. (I would still expect some portion of the Mellanox roadmap to continue short term.)
HStewart - Tuesday, February 4, 2020 - link
You ever thought that Intel is combining what best of Habana and Nervana to make something completely new.