The Snapdragon 865 Performance Preview: Setting the Stage for Flagship Android 2020
by Andrei Frumusanu on December 16, 2019 7:30 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- 5G
- Cortex A77
- Snapdragon 865

Earlier this month we had the pleasure to attend Qualcomm’s Maui launch event of the new Snapdragon 865 and 765 mobile platforms. The new chipsets promise to bring a lot of new upgrades in terms of performance and features, and undoubtedly will be the silicon upon which the vast majority of 2020 flagship devices will base their designs on. We’ve covered the new improvements and changes of the new chipset in our dedicated launch article, so be sure to read that piece if you’re not yet familiar with the Snapdragon 865.
As has seemingly become a tradition with Qualcomm, following the launch event we’ve been given the opportunity to have some hands-on time with the company’s reference devices, and had the chance to run the phones through our benchmark suite. The QRD865 is a reference phone made by Qualcomm and integrates the new flagship chip. The device offers insight into what we should be expecting from commercial devices in 2020, and today’s piece particularly focuses on the performance improvements of the new generation.
- Qualcomm Announces Snapdragon 865 and 765(G): 5G For All in 2020, All The Details
- Qualcomm Windows on Snapdragon: New 7c & 8c SoCs for sub-$800 Laptops
- Quick Bytes: Qualcomm’s Dynamic Spectrum Sharing Demo with 5G and 4G
- Quick Bytes: Qualcomm’s Prediction of 1.4 Billion 5G Smartphones by 2022
- Qualcomm Snapdragon Tech Summit Live Blog: Day One
- Qualcomm Snapdragon Tech Summit Live Blog Day Two: All About Mobile
- Qualcomm Snapdragon Tech Summit Day 3 Live Blog: ACPC and XR
A quick recap of the Snapdragon 865 if you haven’t read the more thorough examination of the changes:
| Qualcomm Snapdragon Flagship SoCs 2019-2020 | |||
| SoC |
Snapdragon 865 |
Snapdragon 855 | |
| CPU | 1x Cortex A77 @ 2.84GHz 1x512KB pL2 3x Cortex A77 @ 2.42GHz 3x256KB pL2 4x Cortex A55 @ 1.80GHz 4x128KB pL2 4MB sL3 @ ?MHz |
1x Kryo 485 Gold (A76 derivative) @ 2.84GHz 1x512KB pL2 3x Kryo 485 Gold (A76 derivative) @ 2.42GHz 3x256KB pL2 4x Kryo 485 Silver (A55 derivative) @ 1.80GHz 4x128KB pL2 2MB sL3 @ 1612MHz |
|
| GPU | Adreno 650 @ 587 MHz +25% perf +50% ALUs +50% pixel/clock +0% texels/clock |
Adreno 640 @ 585 MHz |
|
| DSP / NPU | Hexagon 698 15 TOPS AI (Total CPU+GPU+HVX+Tensor) |
Hexagon 690 7 TOPS AI (Total CPU+GPU+HVX+Tensor) |
|
| Memory Controller |
4x 16-bit CH @ 2133MHz LPDDR4X / 33.4GB/s or @ 2750MHz LPDDR5 / 44.0GB/s 3MB system level cache |
4x 16-bit CH @ 1866MHz LPDDR4X 29.9GB/s 3MB system level cache |
|
| ISP/Camera | Dual 14-bit Spectra 480 ISP 1x 200MP 64MP ZSL or 2x 25MP ZSL 4K video & 64MP burst capture |
Dual 14-bit Spectra 380 ISP 1x 192MP 1x 48MP ZSL or 2x 22MP ZSL |
|
| Encode/ Decode |
8K30 / 4K120 10-bit H.265 Dolby Vision, HDR10+, HDR10, HLG 720p960 infinite recording |
4K60 10-bit H.265 HDR10, HDR10+, HLG 720p480 |
|
| Integrated Modem | none (Paired with external X55 only) (LTE Category 24/22) DL = 2500 Mbps 7x20MHz CA, 1024-QAM UL = 316 Mbps 3x20MHz CA, 256-QAM (5G NR Sub-6 + mmWave) DL = 7000 Mbps UL = 3000 Mbps |
Snapdragon X24 LTE (Category 20) DL = 2000Mbps 7x20MHz CA, 256-QAM, 4x4 UL = 316Mbps 3x20MHz CA, 256-QAM |
|
| Mfc. Process | TSMC 7nm (N7P) |
TSMC 7nm (N7) |
|
The Snapdragon 865 is a successor to the Snapdragon 855 last year, and thus represents Qualcomm’s latest flagship chipset offering the newest IP and technologies. On the CPU side, Qualcomm has integrated Arm’s newest Cortex-A77 CPU cores, replacing the A76-based IP from last year. This year Qualcomm has decided against requesting any microarchitectural changes to the IP, so unlike the semi-custom Kryo 485 / A76-based CPUs which had some differing aspects to the design, the new A77 in the Snapdragon 865 represents the default IP configuration that Arm offers.
Clock frequencies and core cache configurations haven’t changed this year – there’s still a single “Prime” A77 CPU core with 512KB cache running at a higher 2.84GHz and three “Performance” or “Gold” cores with reduced 256KB caches at a lower 2.42GHz. The four little cores remain A55s, and also the same cache configuration as well as the 1.8GHz clock. The L3 cache of the CPU cluster has been doubled from 2 to 4MB. In general, Qualcomm’s advertised 25% performance uplift on the CPU side solely comes from the IPC increases of the new A77 cores.
The GPU this year features an updates Adreno 650 design which increases ALU and pixel rendering units by 50%. The end-result in terms of performance is a promised 25% upgrade – it’s likely that the company is running the new block at a lower frequency than what we’ve seen on the Snapdragon 855, although we won’t be able to confirm this until we have access to commercial devices early next year.
A big performance upgrade on the new chip is the quadrupling of the processing power of the new Tensor cores in the Hexagon 698. Qualcomm advertises 15 TOPS throughput for all computing blocks on the SoC and we estimate that the new Tensor cores roughly represent 10 TOPS out of that figure.

In general, the Snapdragon 865 promises to be a very versatile chip and comes with a lot of new improvements – particularly 5G connectivity and new camera capabilities are promised to be the key features of the new SoC. Today’s focus lies solely on the performance of the chip, so let’s move on to our first test results and analysis.
New Memory Controllers & LPDDR5: A Big Improvement
One of the larger changes in the SoC this generation was the integration of a new hybrid LPDDR5 and LPDDR4X memory controller. On the QRD865 device we’ve tested the chip was naturally equipped with the new LP5 standard. Qualcomm was actually downplaying the importance of LP5 itself: the new standard does bring higher memory speeds providing better bandwidth, however latency should be the same, and power efficiency benefits, while there, shouldn’t be overplayed. Nevertheless, Qualcomm did claim they focused more on improving their memory controllers, and this year we’re finally seeing the new chip address some of the weaknesses exhibited by the past two generations; memory latency.
We had criticised Qualcomm’s Snapdragon 845 and 855 for having quite bad memory latency – ever since the company had introduced their system level cache architecture to the designs, this aspect of the memory subsystem had seen some rather mediocre characteristics. There’s been a lot of arguments in regards to how much this actually affected performance, with Qualcomm themselves naturally downplaying the differences. Arm generally notes a 1% performance difference for each 5ns of latency to DRAM, if the differences are big, it can sum up to a noticeable difference.
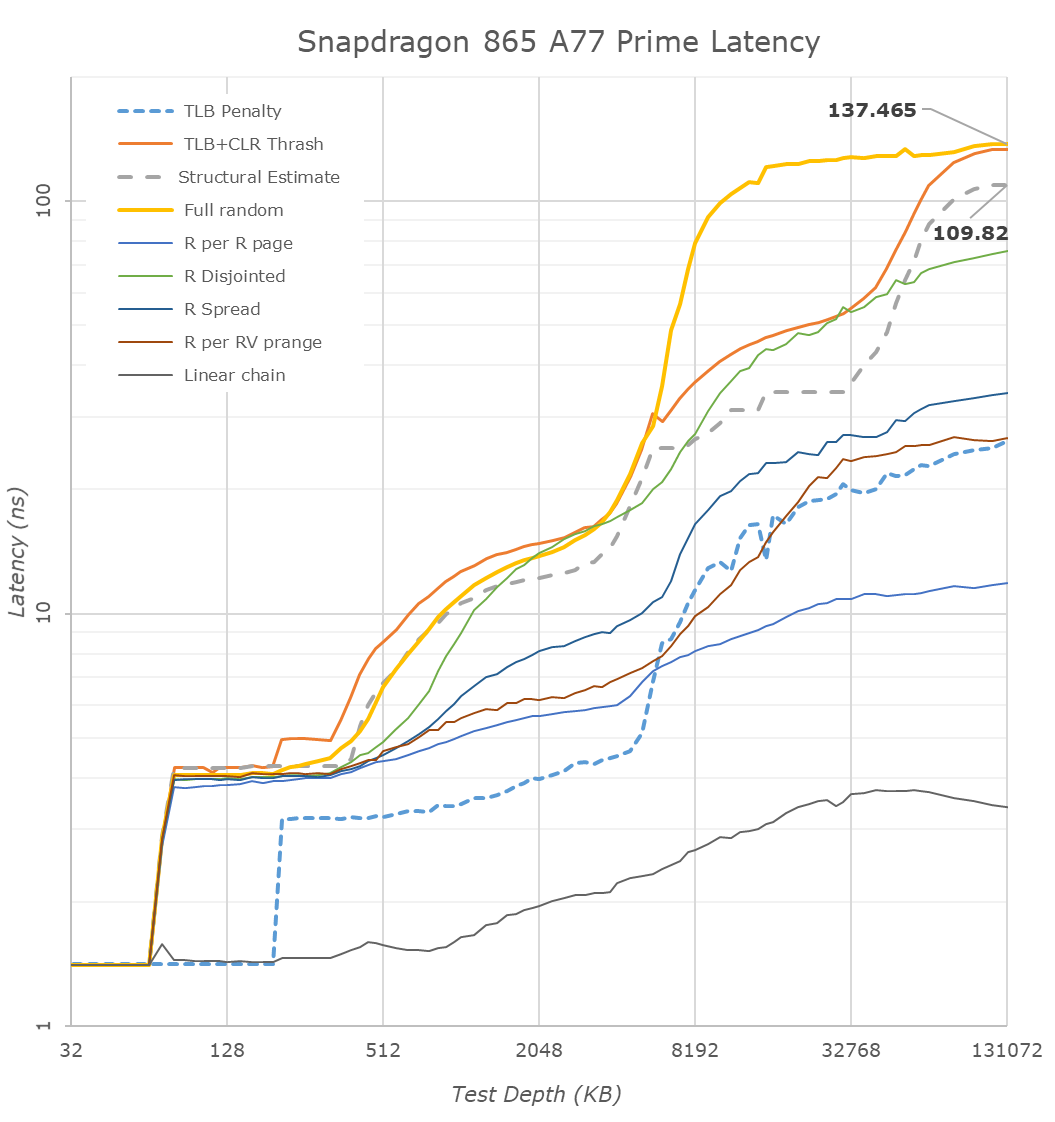
( )
Looking at the new Snapdragon 865, the first thing that pops up when comparing the two latency charts is the doubled L3 cache of the new chip. It’s to be noted that it does look that there’s still some sort of logical partitioning going on and 512KB of the cache may be dedicated to the little cores, as random-access latencies start going up at 1.5MB for the S855 and 3.5MB for the S865.
Further down in the deeper memory regions, we’re seeing some very big changes in latency. Qualcomm has been able to shave off around 35ns in the full random-access test, and we’re estimating that the structural latency of the chip now falls in at ~109ns – a 20ns improvements over its predecessor. While it’s a very good improvements in itself, it’s still a slightly behind the designs of HiSilicon, Apple and Samsung. So, while Qualcomm still is the last of the bunch in regards to its memory subsystem, it’s no longer trailing behind by such a large margin. Keep in mind the results of the Kirin 990 here as we go into more detailed analysis of memory-intensive workloads in SPEC on the next page.
Furthermore, what’s very interesting about Qualcomm’s results in the DRAM region is the behaviour of the TLB+CLR Trash test. This test is always hitting the same cache-line within a page across different, forcing a cache line replacement. The oddity here is that the Snapdragon 865 here behaves very differently to the 855, with the results showcasing a separate “step” in the results between 4MB and ~32MB. This result is more of an artefact of the test only hitting a single cache line per page rather than the chip actually having some sort of 32MB hidden cache. My theory is that Qualcomm has done some sort of optimisation to the cache-line replacement policy at the memory controller level, and instead the test hitting DRAM, it’s actually residing at on the SLC cache. It’s a very interesting result and so far, it’s the first and only chipset to exhibit such behaviour. If it’s indeed the SLC, the latency would fall in at around 25-35ns, with the non-uniform latency likely being a result of the four cache slices dedicated to the four memory controllers.
Overall, it looks like Qualcomm has made rather big changes to the memory subsystem this year, and we’re looking forward to see the impact on performance.








178 Comments
View All Comments
Andrei Frumusanu - Monday, December 16, 2019 - link
You forgot I'm member of the Illuminati, half mole-people from my dad's side and half lizard-man from my mother's side. I love my monthly deep state paycheck alongside the Apple subsidies I get for spreading their narrative. Wait till people find out the earth is really flat.Quantumz0d - Monday, December 16, 2019 - link
LOL. Lawyer manipulation is for their Class Actions KB fiasco, Touch Disease, Error 53..not you (Just clarifying) and idk if you know Louis Rossman on YT. If not I suggest to watch and know how the fleecing is done and consumer is kept in dark always. The revelations of their stranglehold on HW IC chip for supplying to repair services and Lobbying against Repair is enough to understand and gauge the fundamemal pillars of a company and its ethics.Sorry I take ethics and choice/liberty into account over utopian performance and elitist / Luxury status quo stance.
Andrei Frumusanu - Monday, December 16, 2019 - link
I pleaded with you to not go into tangential rants for this article again, yet here we are.Andrei Frumusanu - Monday, December 16, 2019 - link
> How? Just like Geekbench, different compilers are used. Different distribution of loads are made.Please explain to me what the hell "different distributions of loads are made" is meant to mean? You have zero technical rationale behind such statements. All the comparisons here were made with the Clang/LLVM compilers on all platforms - bar the ISA, there is exactly zero difference in the workload logic between the platforms, and Apple's toolchain isn't doing something completely different either that it would suddenly invalidate the comparison.
> You are showing Apple A13 (LOL A13 is faster than the fastest AMD or Intel chip) using Jurassic Spec benchmark?
Yes I am because that is the reality of the matter.
> We are talking about efficiency here, your beloved Apple chip is sucking twice the power than SD855 or SD865 per workload.
And it's finishing the workload than twice as fast, ending up being *almost* as efficient in terms of the energy used by the computation. What matters here is the energy efficiency, not the power efficiency, and in this regard Apple's devices are top of the line.
> While your chart if showing Apple has twice the performance vs SD865, the phone doesn't tell lies.
What's even your point here? Of course the iPhones are significantly faster in loading webpages?
Return here when you have an actual factual argument to present, because right now you just have been repeating complete nonsense.
joms_us - Monday, December 16, 2019 - link
> Please explain to me what the hell "different distributions of loads are made" is meant to mean? You have zero technical rationale behind such statements. All the comparisons here were made with the Clang/LLVM compilers on all platforms - bar the ISA, there is exactly zero difference in the workload logic between the platforms, and Apple's toolchain isn't doing something completely different either that it would suddenly invalidate the comparison.The compiler maybe the same but the scheduler of tasks in Android and Windows are different than in iOS. Many background apps are running simultaneously on Android and Windows machine, how about iOS? Frozen apps? LOL
>Yes I am because that is the reality of the matter.
Only matters to you, not in outside world. If you really think A9 has better IPC than Ryzen or Skylake, why don't you join the Apple engineers and build the fastest gaming/productivity PC with Apple A9 chip and sell it like hotcakes? No? Cannot t be? Even Apple doesn't claim their SoC is faster than even low end desktop today LOL. Even milking the customers with overpriced Macs with "Intel" inside.
> And it's finishing the workload than twice as fast, ending up being *almost* as efficient in terms of the energy used by the computation. What matters here is the energy efficiency, not the power efficiency, and in this regard Apple's devices are top of the line.
What matters is how fast it can finish the whole task not each micro-workload nonsense. If I want to zip and upload a file or encode and upload a video, I only care how fast it will finish the whole task and for that matter. If I want to play games, do I care how the fast the damn phone will compute the vector, pixel location, math operations etc? I only care how elegant, smooth and how fast the gaming experience will be.
iPhone is not twice as fast as loading any web page, any consumer app or even exporting or transcoding videos. Different apps yield different results, you are showing one worthless primitive benchmark where iPhone is fast, but out there, hundreds or thousands of different apps and website are showing the opposite results.
Here is one or two for you, one is showing twice the performance over the other =D
https://youtu.be/ay9V5Ec8eiY?t=529
https://youtu.be/DtSgdrKztGk?t=432
Andrei Frumusanu - Monday, December 16, 2019 - link
> the scheduler of tasks in Android and Windows are different than in iOS.The scheduler isn't any different, because the scheduler doesn't do anything when there's only a single thread on a core to be run. There is literally no scheduling.
> If you really think A9 has better IPC than Ryzen or Skylake
Correction, I don't really just think it, I know it.
> What matters is how fast it can finish the whole task not each micro-workload nonsense.
The whole SPEC suite takes exactly an hour to complete, so quit with the micro nonsense if you have no idea what's even being tested here.
> Here is one or two for you, one is showing twice the performance over the other =D
Both phones don't even use the freaking CPU when transcoding videos - they're both offloaded using the dedicated fixed function video encoders much like you can offload encoding on desktop PCs to your GPU's encoders, instead of doing it inefficiently on the CPU.
You have absolutely ZERO understanding of what's going on here.
joms_us - Monday, December 16, 2019 - link
> The scheduler isn't any different, because the scheduler doesn't do anything when there's only a single thread on a core to be run. There is literally no scheduling.Then the SoC is not maximized but underperforming.
> Correction, I don't really just think it, I know it.
Sure you do, now where is the fastest processor in this planet? Where is our A9-powered gaming PC LOL.
> The whole SPEC suite takes exactly an hour to complete, so quit with the micro nonsense if you have no idea what's even being tested here.
Just goes to show how primitive your tool is. 2020 is just around the corner, here you are still using a 2006 tool. This is like claiming Wolfdale is faster than Ryzen because it can finish 1M SuperPI faster LOL.
Dug - Monday, December 16, 2019 - link
You really don't have any argument because you really aren't sure what you are talking about.joms_us - Monday, December 16, 2019 - link
Am I or you? Isn't it clear that SPEC result does not translate to real-world? Where is the double performance as shown here? Show us proof that iPhone has twice the performance, I've posted links with two Android phones decimating iPhone 11.Sure you can claim all day you want that iPhone is the fastest phone via SPEC LOL, I'd rather see it translate to actual performance, not imaginary numbers.
cha0z_ - Monday, December 23, 2019 - link
You clearly have no idea what you are talking about. Dunno why Andrei dedicated so much of his time trying to explain to you in primitive language what's going on (so you can understand).