The Toshiba XG6 1TB SSD Review: Our First 96-Layer 3D NAND SSD
by Billy Tallis on September 6, 2018 8:15 AM ESTMixed Random Performance
Our test of mixed random reads and writes covers mixes varying from pure reads to pure writes at 10% increments. Each mix is tested for up to 1 minute or 32GB of data transferred. The test is conducted with a queue depth of 4, and is limited to a 64GB span of the drive. In between each mix, the drive is given idle time of up to one minute so that the overall duty cycle is 50%.
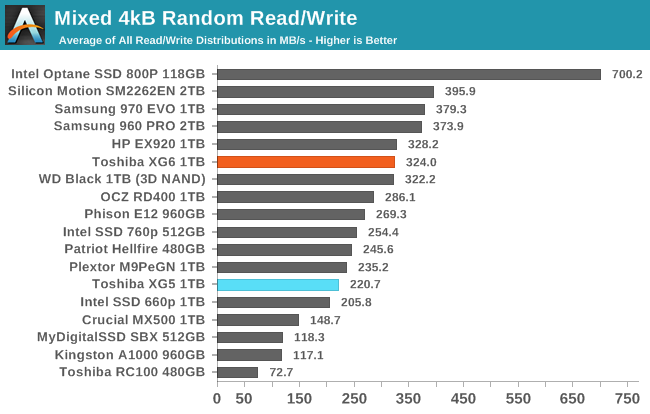
The mixed random I/O performance of the Toshiba XG6 jumps by about 47% compared to the XG5, making it competitive with most current high-end TLC drives.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
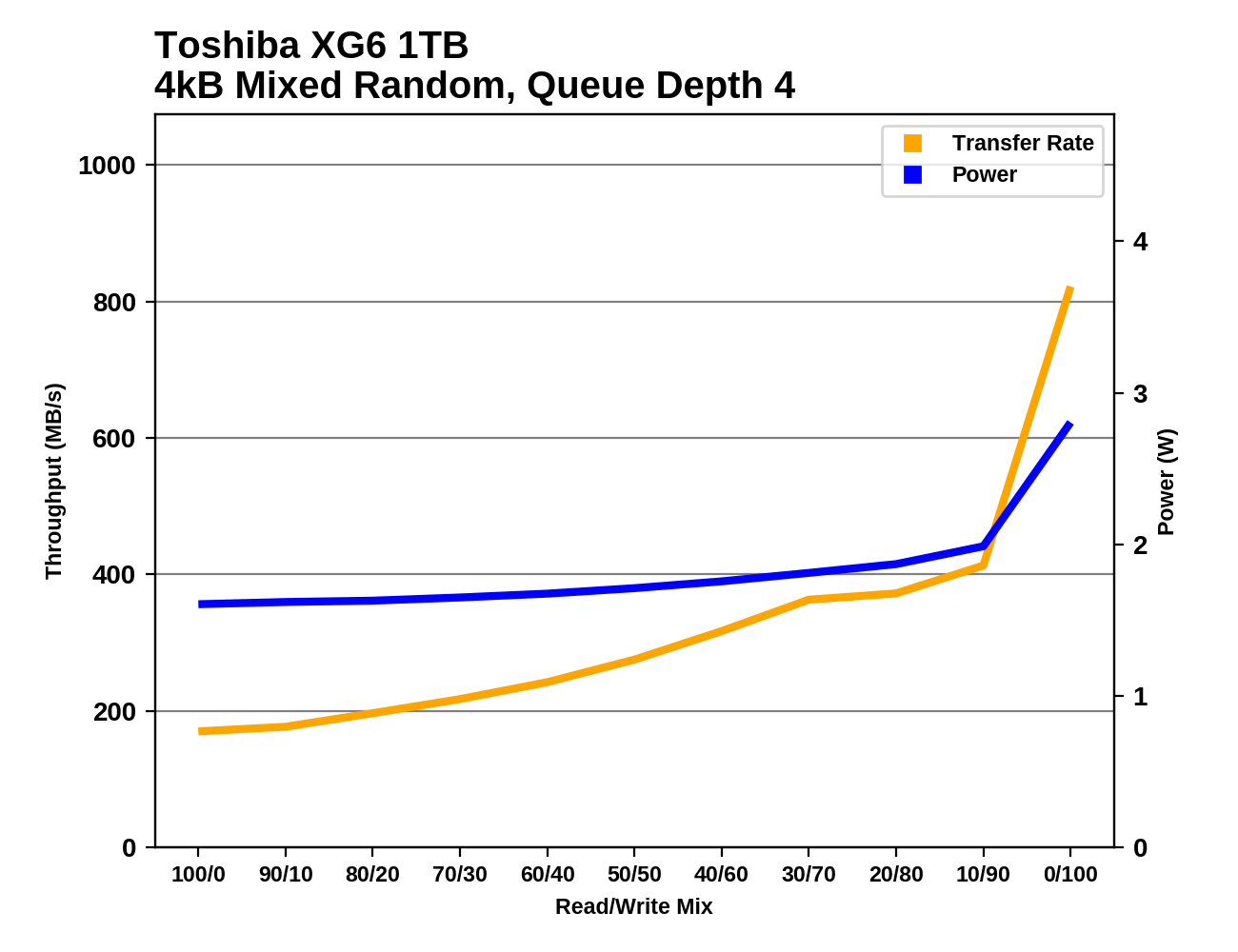
Thanks to the big performance boost at almost no cost in added power consumption, the Toshiba XG6 takes an 11% lead over the nearest competition in power efficiency on this test.
 |
|||||||||
The Toshiba XG6 is able to increase performance throughout the test as more writes are added to the workload, with much more performance growth than the XG5 showed. The performance growth falters a bit near the end of the test but the XG6 still delivers the expected performance spike with the final phase of the test as the workload shifts to pure writes.
Mixed Sequential Performance
Our test of mixed sequential reads and writes differs from the mixed random I/O test by performing 128kB sequential accesses rather than 4kB accesses at random locations, and the sequential test is conducted at queue depth 1. The range of mixes tested is the same, and the timing and limits on data transfers are also the same as above.

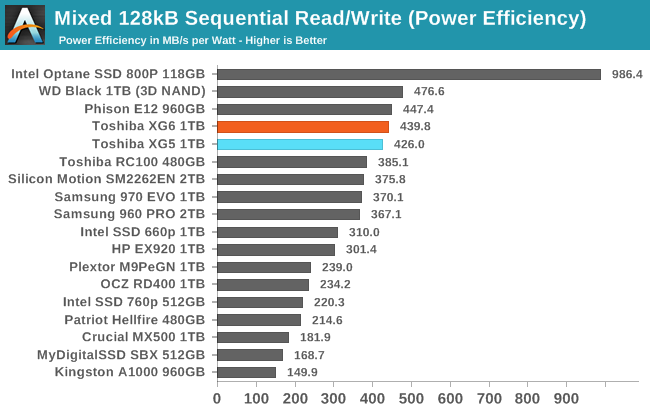
The mixed sequential I/O performance of the XG6 is a bit faster than the XG5, but not enough to boost it up to the top tier of drives. The relatively poor QD1 sequential performance compared to the competition is holding back the XG6 here.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
In spite of mid-tier performance, the XG6 still manages very good power efficiency that is a bit better than the XG5 and not too far behind the WD Black. However, the XG6 will also soon be beat by numerous upcoming Phison E12 drives even if the latter are still using the older 64-layer Toshiba 3D TLC.
 |
|||||||||
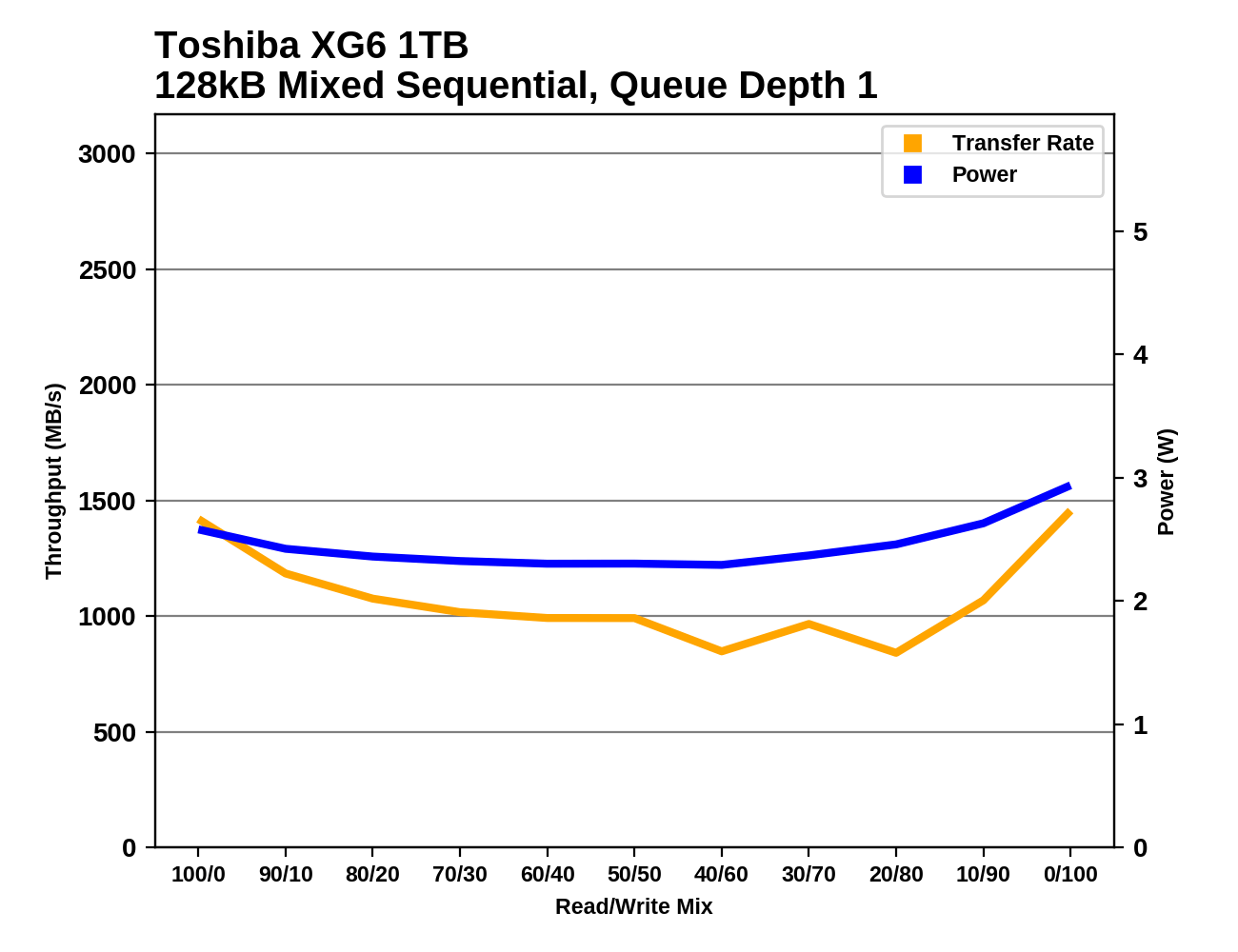
Slow QD1 read speeds are the main factor keeping the XG6 from matching the overall performance scores of the top tier of drives. The XG6 also shows a bit of performance variation during the second half of the test due to garbage collection or a full SLC cache, but the impact is not severe.








31 Comments
View All Comments
Valantar - Friday, September 7, 2018 - link
AFAIK they're very careful which patches are applied to test beds, and if they affect performance, older drives are retested to account for this. Benchmarks like this are never really applicable outside of the system they're tested in, but the system is designed to provide a level playing field and repeatable results. That's really the best you can hope for. Unless the test bed has a consistent >10% performance deficit to most other systems out there, there's no reason to change it unless it's becoming outdated in other significant areas.iwod - Thursday, September 6, 2018 - link
So we are limited by PCI-e interface again. Since the birth of SSD, we pushed past SATA 3Gbps / 6Gbps, than PCI-E 2.0 x4 2GB/S and now PCI-E 3.0, 4GB/s.When are we going to get PCI-E 4.0, or since 5.0 is only just around the corner may as well wait for it. That is 16GB/s, plenty of room for SSD maker to figure out how to get there.
MrSpadge - Thursday, September 6, 2018 - link
There's no need to rush there. If you need higher performance, use multiple drives. Maybe on a HEDT or Enterprise platform if you need extreme performance.But don't be surprised if that won't help your PC as much as you thought. The ultimate limit currently is a RAMdisk. Launch a game from there or install some software - it's still surprisingly slow, because the CPU becomes the bottleneck. And that already applies to modern SSDs, which is obvious in benchmarks which test copying, installing or application launching etc.
abufrejoval - Friday, September 7, 2018 - link
Could also be the OS or the RAMdisk driver. When I finished building my 128GB 18-Core system with a FusionIO 2.4 TB leftover and 10Gbit Ethernet, I obviously wanted to bench it on Windows and Linux. I was rather shocked to see how slow things generally remained and how pretty much all these 36 HT-"CPU"s were just yawning.In the end I never found out, if it was the last free version (3.4.8) version of SoftPerfect's RAM disk that didn' seem to make use of all four memory Xeon E5 memory channels, or some bottleneck in Windows (never seen Windows update user more than a single core), but I never got anywhere near the 70GB/s Johan had me dream of (https://www.anandtech.com/show/8423/intel-xeon-e5-... Don't think I even saturated the 10Gbase-T network, if I recall correctly.
It was quite different in many cases on Linux, but I do remember running an entire Oracle database on tmpfs once, and then an OLTP benchmark on that... again earning myself a totally bored system under the most intensive benchmark hammering I could orchestrate.
There are so many serialization points in all parts of that stack, you never really get the performance you pay for until someone has gone all the way and rewritten the entire software stack from scratch for parallel and in-memory.
Latency is the killer for performance in storage, not bandwidth. You can saturate all bandwidth capacities with HDDs, even tape. Thing is, with dozens (modern CPUs) or thousands (modern GPGPUs) SSDs *become tape*, because of the latencies incurred on non-linear access patterns.
That's why after NVMe, NV-DIMMs or true non-volatile RAM is becoming so important. You might argue that a cache line read from main memory still looks like a tape library change against the register file of an xPU, but it's still way better than PCIe-5-10 with a kernel based block layer abstraction could ever be.
Linear speed and loops are dead: If you cannot unroll, you'll have to crawl.
halcyon - Monday, September 10, 2018 - link
Thank you for writing this.Quantum Mechanix - Monday, September 10, 2018 - link
Awesome write up- my favorite kind of comment, where I walk away just a *tiny* less ignorant. Thank you! :)DanNeely - Thursday, September 6, 2018 - link
We've been 3.0 x4 bottlenecked for a few years.From what I've read about the implementing 4.0/5.0 on a mobo I'm not convinced we'll see them on consumer boards, at least not in its current form. The maximum PCB trace length without expensive boosters is too short, AIUI 4.0 is marginal to the top PCIe slot/chipset and 5.0 would need signal boosters even to go that far. Estimates I've seen were $50-100 (I think for an x16 slot) to make a 4.0 slot and several times that for 5.0. Cables can apparently go several times longer than PCB traces while maintaining signal quality, but I'm skeptical about them getting snaked around consumer mobos.
And as MrSpadge pointed out in many applications scale out wider is an option, and what I've read that Enterprise Storage is looking at. Instead of x4 slots that have 2/4x the bandwidth of current ones that market is more interested in 5.0 x1 connections that have the same bandwidth as current devices but which would allow them to connect 4 times as many drives. That seems plausible to me since enterprise drive firmware is generally tuned for steady state performance not bursts and most of them don't come as close to saturating buses as high end consumer drives do for shorter/more intermitant workloads.
abufrejoval - Friday, September 7, 2018 - link
I guess that's why they are working on silicon photonics: PCB voltage levels, densities, layers, trace lengths... Whereever you look there are walls of physics rising into mountains. If only PCBs weren't so much cheaper than silicon interposers, photonics and other new and rare things!darwiniandude - Sunday, September 9, 2018 - link
Any testing under windows on current MacBook Pro hardware? Those SSD's I would've thought are much much faster, but I'd love to see the same test on them.halcyon - Monday, September 10, 2018 - link
Thanks for the review. For future, could you consider segregating the drives into different tiers based on results, e.g. video editing, dB, generic OS/boot/app drive, compilation, whatnot.Now it seems that one drive is better in ine thing, and another drive in anither scenario. But not having your in-depth knowledge, makes it harder to assess which drive would be closest to optimal in which scenario.