Retesting AMD Ryzen Threadripper’s Game Mode: Halving Cores for More Performance
by Ian Cutress on August 17, 2017 12:01 PM ESTCPU Office Tests
The office programs we use for benchmarking aren't specific programs per-se, but industry standard tests that hold weight with professionals. The goal of these tests is to use an array of software and techniques that a typical office user might encounter, such as video conferencing, document editing, architectural modeling, and so on and so forth.
All of our benchmark results can also be found in our benchmark engine, Bench.
Chromium Compile (v56)
Our new compilation test uses Windows 10 Pro, VS Community 2015.3 with the Win10 SDK to compile a nightly build of Chromium. We've fixed the test for a build in late March 2017, and we run a fresh full compile in our test. Compilation is the typical example given of a variable threaded workload - some of the compile and linking is linear, whereas other parts are multithreaded.
For our test, we compile a version of v56 under MSVC and report the time in 'Compiles per Day', a more scalable metric to represent over time. Other publications might perfom this test differently (Ars Technica uses a clang-cl compiler with VC++ linking, for example).
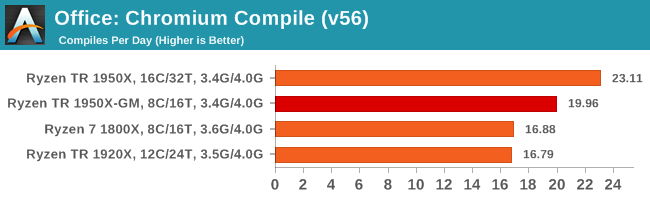
One of the interesting data points in our test is the Compile. Because this test requires a lot of cross-core communication and DRAM, we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores.
PCMark8: link
Despite originally coming out in 2008/2009, Futuremark has maintained PCMark8 to remain relevant in 2017. On the scale of complicated tasks, PCMark focuses more on the low-to-mid range of professional workloads, making it a good indicator for what people consider 'office' work. We run the benchmark from the commandline in 'conventional' mode, meaning C++ over OpenCL, to remove the graphics card from the equation and focus purely on the CPU. PCMark8 offers Home, Work and Creative workloads, with some software tests shared and others unique to each benchmark set.
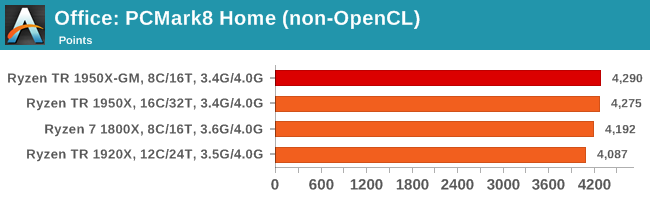
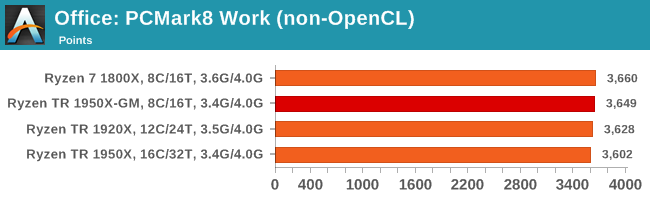
Strangely, PCMark 8's Creative test seems to be failing across the board. We're trying to narrow down the issue.








104 Comments
View All Comments
Lieutenant Tofu - Friday, August 18, 2017 - link
"... we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores. "Would you mind elaborating on this? How does the proportion of cores per CCX affect performance?
JasonMZW20 - Sunday, August 20, 2017 - link
The only thing I can think of is CCX cache locality. Given a choice, you want more cores per CCX to keep data on that CCX rather than using cross-communication between CCXes through L2/L3. Once you have to communicate with the other CCX, you automatically incur a higher average latency penalty, which in some cases, is also a performance penalty (esp. if data keeps moving between the two CCXes).Lieutenant Tofu - Friday, August 18, 2017 - link
On the compile test (prev page):"... we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores. "
Would you mind elaborating on this? How does the proportion of cores per CCX affect performance?
rhoades-brown - Friday, August 18, 2017 - link
This gaming mode intrigues me greatly- the article states that the PCIe lanes and memory controller is still enabled, but the cores are turned off as shown in this diagram:http://images.anandtech.com/doci/11697/kevin_lensi...
If these are two complete processors on one package (as the diagrams and photos show), what impact does having gaming mode enabled and a PCIe device connected to the PCIe controller on the 'inactive' side? The NUMA memory latency seems to be about 1.35 surely this must affect the PCIe devices too- further how much bandwidth is there between the two processors? Opteron processors use HyperTransport for communication, do these do the same?
I work in the server world and am used to NUMA systems- for two separate processor packages in a 2 socket system, cross-node memory access times is normally 1.6x that of local memory access. For ESXi hosts, we also have particular PCIe slots that we place hardware in, to ensure that the different controllers are spread between PCIe controllers ensuring the highest level of availability due to hardware issue and peek performance (we are talking HBAs, Ethernet adapters, CNAs here). Although, hardware reliability is not a problem in the same way in a Threadripper environment, performance could well be.
I am intrigued to understand how this works in practice. I am considering building one of these systems out for my own home server environment- I yet to see any virtualisation benchmarks.
versesuvius - Friday, August 18, 2017 - link
So, what is a "Game"? Uses DirectX? Makes people act stupidly? Is not capable of using what there is? Makes available hardware a hindrance to smooth computing? Looks like a lot of other apps (that are not "Game") can benefit from this "Gaming Mode".msroadkill612 - Friday, August 18, 2017 - link
A shame no Vega GPU in the mix :(It may have revealed interesting synergies between sibling ryzen & vega processors as a bonus.
BrokenCrayons - Friday, August 18, 2017 - link
The only interesting synergy you'd get from a Threadripper + Vega setup is an absurdly high electrical demand and an angry power supply. Nothing makes less sense than throwing a 180W CPU plus a 295W GPU at a job that can be done with a 95W CPU and a 180W GPU just as well in all but a few many-threaded workloads (nevermind the cost savings on the CPU for buying Ryzen 7 or a Core i7).versesuvius - Friday, August 18, 2017 - link
I am not sure if I am getting it right, but apparently if the L3 cache on the first Zen core is full and the core has to go to the second core's L3 cache there is an increase in latency. But if the second core is power gated and does not take any calls, then the increase in latency is reduced. Is it logical to say that the first core has to clear it with the second core before it accesses the second core's cache and if the second core is out it does not have to and that checking with the second core does not take place and so latency is reduced? Moving on if the data is not in the second core's cache then the first core has to go to DRAM accessing which supposedly does not need clearance from the second core. Or does it always need to check first with the second core and then access even the DRAM?BlackenedPies - Friday, August 18, 2017 - link
Would Threadripper be bottlenecked by dual channel RAM due to uneven memory access between dies? Is the optimal 2 DIMM setup one per die channel or two on one die?Fisko - Saturday, August 19, 2017 - link
Anyone working on daily basis just to view and comment pdf won't use acrobat DC. Exception can be using OCR for pdf. Pdfxchange viewer uses more threads and opens pdf files much faster than Adobe DC. I regularly open files from 25 to 80 mb of CAD pdf files and difference is enormous.