Retesting AMD Ryzen Threadripper’s Game Mode: Halving Cores for More Performance
by Ian Cutress on August 17, 2017 12:01 PM ESTCPU Web Tests
One of the issues when running web-based tests is the nature of modern browsers to automatically install updates. This means any sustained period of benchmarking will invariably fall foul of the 'it's updated beyond the state of comparison' rule, especially when browsers will update if you give them half a second to think about it. Despite this, we were able to find a series of commands to create an un-updatable version of Chrome 56 for our 2017 test suite. While this means we might not be on the bleeding edge of the latest browser, it makes the scores between CPUs comparable.
All of our benchmark results can also be found in our benchmark engine, Bench.
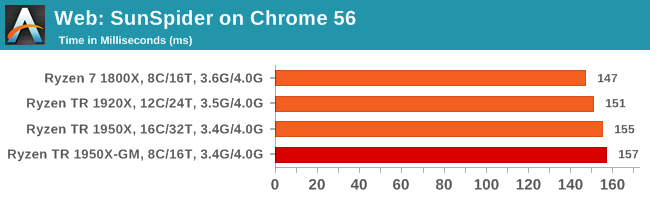
SunSpider 1.0.2: link
The oldest web-based benchmark in this portion of our test is SunSpider. This is a very basic javascript algorithm tool, and ends up being more a measure of IPC and latency than anything else, with most high-performance CPUs scoring around about the same. The basic test is looped 10 times and the average taken. We run the basic test 4 times.
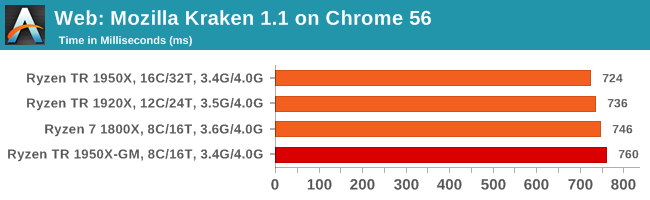
Mozilla Kraken 1.1: link
Kraken is another Javascript based benchmark, using the same test harness as SunSpider, but focusing on more stringent real-world use cases and libraries, such as audio processing and image filters. Again, the basic test is looped ten times, and we run the basic test four times.
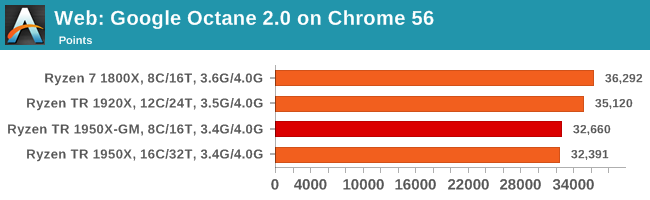
Google Octane 2.0: link
Along with Mozilla, as Google is a major browser developer, having peak JS performance is typically a critical asset when comparing against the other OS developers. In the same way that SunSpider is a very early JS benchmark, and Kraken is a bit newer, Octane aims to be more relevant to real workloads, especially in power constrained devices such as smartphones and tablets.
WebXPRT 2015: link
While the previous three benchmarks do calculations in the background and represent a score, WebXPRT is designed to be a better interpretation of visual workloads that a professional user might have, such as browser based applications, graphing, image editing, sort/analysis, scientific analysis and financial tools.
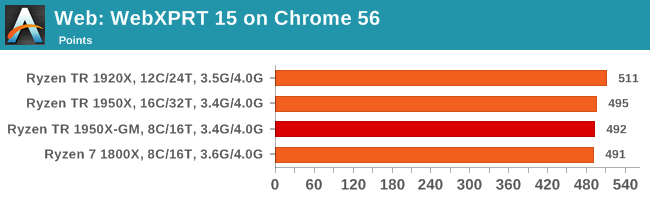
Overall, all of our web benchmarks show a similar trend. Very few web frameworks offer multi-threading – the browsers themselves are barely multi-threaded at times – so Threadripper's vast thread count is underutilized. What wins the day on the web are a handful of fast cores with high single-threaded performance, and it becomes a balance between cores and cross-core communication.








104 Comments
View All Comments
Lieutenant Tofu - Friday, August 18, 2017 - link
"... we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores. "Would you mind elaborating on this? How does the proportion of cores per CCX affect performance?
JasonMZW20 - Sunday, August 20, 2017 - link
The only thing I can think of is CCX cache locality. Given a choice, you want more cores per CCX to keep data on that CCX rather than using cross-communication between CCXes through L2/L3. Once you have to communicate with the other CCX, you automatically incur a higher average latency penalty, which in some cases, is also a performance penalty (esp. if data keeps moving between the two CCXes).Lieutenant Tofu - Friday, August 18, 2017 - link
On the compile test (prev page):"... we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores. "
Would you mind elaborating on this? How does the proportion of cores per CCX affect performance?
rhoades-brown - Friday, August 18, 2017 - link
This gaming mode intrigues me greatly- the article states that the PCIe lanes and memory controller is still enabled, but the cores are turned off as shown in this diagram:http://images.anandtech.com/doci/11697/kevin_lensi...
If these are two complete processors on one package (as the diagrams and photos show), what impact does having gaming mode enabled and a PCIe device connected to the PCIe controller on the 'inactive' side? The NUMA memory latency seems to be about 1.35 surely this must affect the PCIe devices too- further how much bandwidth is there between the two processors? Opteron processors use HyperTransport for communication, do these do the same?
I work in the server world and am used to NUMA systems- for two separate processor packages in a 2 socket system, cross-node memory access times is normally 1.6x that of local memory access. For ESXi hosts, we also have particular PCIe slots that we place hardware in, to ensure that the different controllers are spread between PCIe controllers ensuring the highest level of availability due to hardware issue and peek performance (we are talking HBAs, Ethernet adapters, CNAs here). Although, hardware reliability is not a problem in the same way in a Threadripper environment, performance could well be.
I am intrigued to understand how this works in practice. I am considering building one of these systems out for my own home server environment- I yet to see any virtualisation benchmarks.
versesuvius - Friday, August 18, 2017 - link
So, what is a "Game"? Uses DirectX? Makes people act stupidly? Is not capable of using what there is? Makes available hardware a hindrance to smooth computing? Looks like a lot of other apps (that are not "Game") can benefit from this "Gaming Mode".msroadkill612 - Friday, August 18, 2017 - link
A shame no Vega GPU in the mix :(It may have revealed interesting synergies between sibling ryzen & vega processors as a bonus.
BrokenCrayons - Friday, August 18, 2017 - link
The only interesting synergy you'd get from a Threadripper + Vega setup is an absurdly high electrical demand and an angry power supply. Nothing makes less sense than throwing a 180W CPU plus a 295W GPU at a job that can be done with a 95W CPU and a 180W GPU just as well in all but a few many-threaded workloads (nevermind the cost savings on the CPU for buying Ryzen 7 or a Core i7).versesuvius - Friday, August 18, 2017 - link
I am not sure if I am getting it right, but apparently if the L3 cache on the first Zen core is full and the core has to go to the second core's L3 cache there is an increase in latency. But if the second core is power gated and does not take any calls, then the increase in latency is reduced. Is it logical to say that the first core has to clear it with the second core before it accesses the second core's cache and if the second core is out it does not have to and that checking with the second core does not take place and so latency is reduced? Moving on if the data is not in the second core's cache then the first core has to go to DRAM accessing which supposedly does not need clearance from the second core. Or does it always need to check first with the second core and then access even the DRAM?BlackenedPies - Friday, August 18, 2017 - link
Would Threadripper be bottlenecked by dual channel RAM due to uneven memory access between dies? Is the optimal 2 DIMM setup one per die channel or two on one die?Fisko - Saturday, August 19, 2017 - link
Anyone working on daily basis just to view and comment pdf won't use acrobat DC. Exception can be using OCR for pdf. Pdfxchange viewer uses more threads and opens pdf files much faster than Adobe DC. I regularly open files from 25 to 80 mb of CAD pdf files and difference is enormous.