Retesting AMD Ryzen Threadripper’s Game Mode: Halving Cores for More Performance
by Ian Cutress on August 17, 2017 12:01 PM ESTCPU Office Tests
The office programs we use for benchmarking aren't specific programs per-se, but industry standard tests that hold weight with professionals. The goal of these tests is to use an array of software and techniques that a typical office user might encounter, such as video conferencing, document editing, architectural modeling, and so on and so forth.
All of our benchmark results can also be found in our benchmark engine, Bench.
Chromium Compile (v56)
Our new compilation test uses Windows 10 Pro, VS Community 2015.3 with the Win10 SDK to compile a nightly build of Chromium. We've fixed the test for a build in late March 2017, and we run a fresh full compile in our test. Compilation is the typical example given of a variable threaded workload - some of the compile and linking is linear, whereas other parts are multithreaded.
For our test, we compile a version of v56 under MSVC and report the time in 'Compiles per Day', a more scalable metric to represent over time. Other publications might perfom this test differently (Ars Technica uses a clang-cl compiler with VC++ linking, for example).
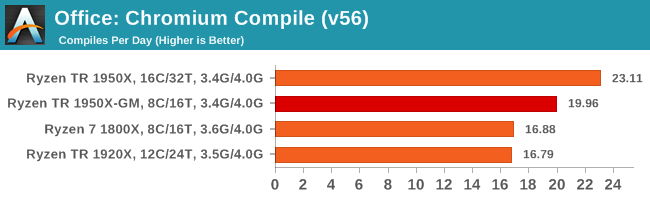
One of the interesting data points in our test is the Compile. Because this test requires a lot of cross-core communication and DRAM, we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores.
PCMark8: link
Despite originally coming out in 2008/2009, Futuremark has maintained PCMark8 to remain relevant in 2017. On the scale of complicated tasks, PCMark focuses more on the low-to-mid range of professional workloads, making it a good indicator for what people consider 'office' work. We run the benchmark from the commandline in 'conventional' mode, meaning C++ over OpenCL, to remove the graphics card from the equation and focus purely on the CPU. PCMark8 offers Home, Work and Creative workloads, with some software tests shared and others unique to each benchmark set.
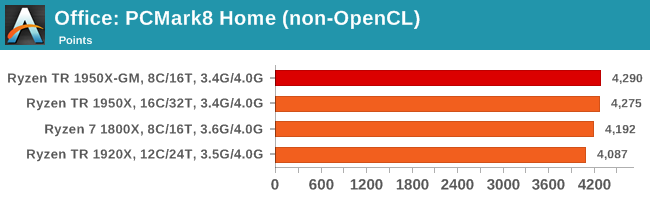
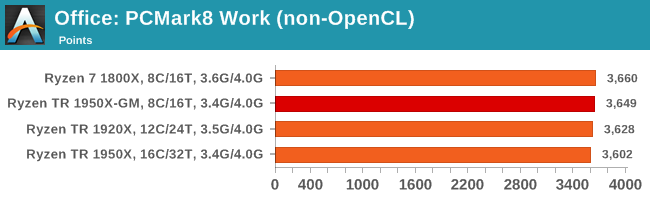
Strangely, PCMark 8's Creative test seems to be failing across the board. We're trying to narrow down the issue.








104 Comments
View All Comments
silverblue - Friday, August 18, 2017 - link
I'd like to see what happens when you manually set a 2+2+2+2 core configuration, instead of enabling Game Mode. From what I've read, Game Mode destroys memory bandwidth but yields better latency, however it's not answering whether Zen cores can really benefit from the extra bandwidth that a quad-channel memory interface affords.Alternatively, just clock the 1950 and 1920 identically, and see if the 1920's per-core performance is any higher.
KAlmquist - Friday, August 18, 2017 - link
“One of the interesting data points in our test is the Compile. Because <B>this test requires a lot of cross-core communication</B> and DRAM, we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores.”Generally speaking, copmpilers are single threaded, so the parallelism in a software build comes from compiling multiple source files in parallel, meaning the cross-core communication is minimal. I have no idea what MSVC is doing here, can you explain? In any case, while I appreciate you including a software development benchmark, the one you've chosen would seem to provide no useful information to anyone who doesn't use MSVC.
peevee - Friday, August 18, 2017 - link
I use MSVC and it scales pretty well if you are using it right. They are doing something wrong.KAlmquist - Saturday, August 19, 2017 - link
Thanks. It makes sense that MSVC would scale about as well as any other build environment.ARS Technica also benchmarked a Chromium build, which I think uses MSVC, but uses the Google tools GN and Ninja to manage the build. They get:
Ryzen 1800X (8 cores) - 9.8 build/day
Threadripper 1920X (12 cores) - 16.7 build/day
Threadripper 1950X (16 cores) - 18.6 build/day
Very good speedup with the 1920X over the 1800X, but not so much going from the 1920X to the 1950X. Perhaps the benchmark is dependent on memory bandwidth and L3 cache.
Timur Born - Friday, August 18, 2017 - link
Thanks for the tests!I would have liked to see a combination of both being tested: Game Mode to switch off the second die and SMT disabled. That way 4 full physical cores with low latency memory access would have run the games.
Hopefully modern titles don't benefit from this, but some more "legacy" ones might like this setup even more.
Timur Born - Friday, August 18, 2017 - link
Sorry, I meant 8 cores, aka 8/8 cores mode.mat9v - Friday, August 18, 2017 - link
I wish someone had an inclination to test creative mode but with games pinned to one module. It is essentially NUMA mode but with all cores active.Or just enable SMT that is disabled in Gaming Mode - we actually then get a Ryzen 1800X CPU that overclocks well but with possibly higher performance due to all system task running on different module (if we configure system that way) and unencumbered access to more PCIEx lines.
peevee - Friday, August 18, 2017 - link
Yes, that would be interesting.c:\>start /REALTIME /NODE 0 /AFFINITY 5555 you_game_here.exe
mat9v - Friday, August 18, 2017 - link
I think I would start it on node 1 is anything since system task would be at default running on node 0.Mask 5555? Wouldn't it be AAAA - for 8 cores (8 threads) and FFFF for 8 cores (16 threads)?
peevee - Friday, August 18, 2017 - link
The mask 5555 assumes that SMT is enabled. Otherwise it should be FF.When SMT is enabled, 5555 and AAAA will allocate threads to the same cores, just different logical CPUs.
Where system threads will be run is system dependent, nothing prevents Windows from running them on NODE 1. /NODE 0 allows to run whether or not you actually have multiple NUMA nodes.
With /REALTIME Windows will have hard time allocating anything on those logical CPUs, but can use the same cores with other logical CPUs, so yes, technically it will affect results. But unless you load it with something, the difference should not be significant - things like cache and memory bus contention are more important anyway and don't care on which cores you run.