Exploring DynamIQ and ARM’s New CPUs: Cortex-A75, Cortex-A55
by Matt Humrick on May 29, 2017 12:00 AM EST- Posted in
- Smartphones
- CPUs
- Arm
- Mobile
- Cortex
- DynamIQ
- Cortex A75
- Cortex A55
Cortex-A75 Microarchitecture
The Cortex-A75 is the newest member of ARM’s Sophia family of CPUs, which also includes the A73, A17, and A12. It’s no surprise then that the A75 and A73 have much in common just like the A72 and A57 before them (both of which belong to the Austin CPU family); however, ARM’s focus has shifted from improving power efficiency and thermal headroom for A73 to improving performance and adding new features for A75. ARM addressed its performance goals through significant changes to the pipeline and support for DynamIQ, while the new features are a byproduct of moving from the ARMv8.0 architecture to ARMv8.2. For this article, I’m primarily going to focus on what’s new for A75, so I recommend reading our introduction to the A73 to get a more complete understanding of the A75 microarchitecture.
The A75 uses a relatively short 11-13+ stage (depending on instruction type) out-of-order pipeline similar to the A73. Instruction fetch is still 4 stages and the decoder is still able to decode most instructions in a single cycle, with µops destined for the NEON/FP (floating-point) pipelines requiring an additional decode stage; however, moving to 3-wide decode makes the A75 is a wider machine than A73, a big change that will be discussed in greater detail below.
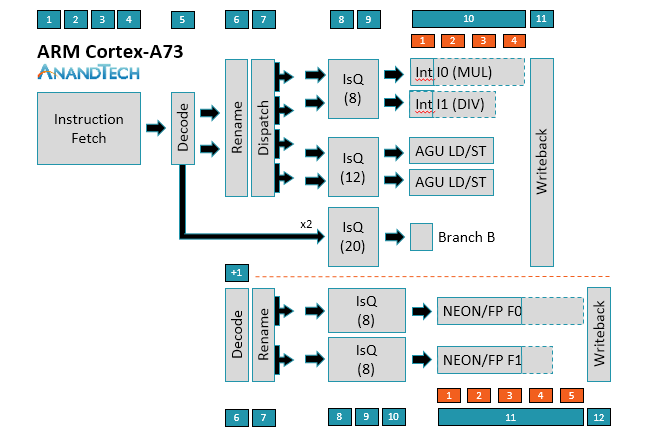
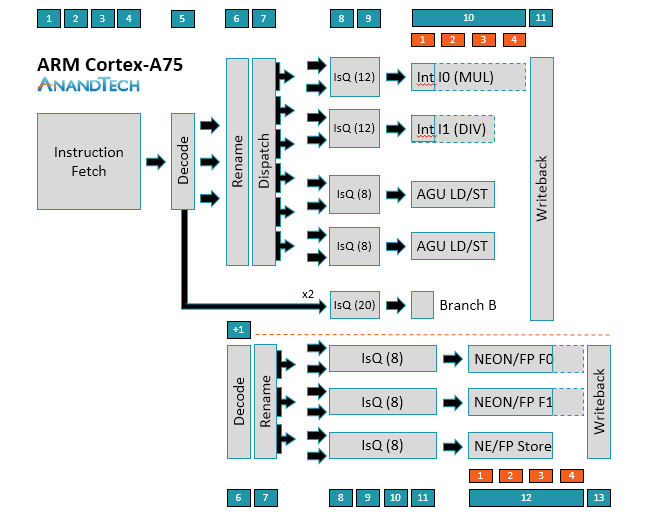
The ability to decode up to 3 instructions/cycle means A75 can now dispatch up to 6 µops/cycle instead of 4 µops/cycle for A73. On the integer side, the A75 can feed up to 2 µops into each issue queue. Instead of shared issue queues for the 2 ALUs and 2 AGUs, each pipe in A75 gets its own issue queue with more entries. This allows the A75 to be more speculative, improving its ability to execute instructions out of order and continue operation during an L1 D-cache miss that hits in L2, for example. The peak issue rate increases to 8 µops/cycle, 1 for each pipe.
As the diagrams for A73/A75 show, simple branch µops can bypass Rename and Dispatch, effectively removing 2 stages of latency; however, more complex branch instructions that require access to registers can spawn additional branch, AGU, and ALU µops that require passing through Rename/Dispatch, with some additional complexity hidden within the Rename stage.
Moving to the NEON/FP side, you’ll notice that there’s no Dispatch stage for A73/A75. Obviously, µops are still being pushed into the issue queues, and there’s still load balancing between queues, but it’s handled differently and one reason why the issue queues are 1-2 stages longer than those on the integer side.
There have been some changes to the NEON/FP side as well. The A75 can now “dispatch” up to 3 µops/cycle and sink up to 2 µops into each issue queue, which grow to 4 stages deep instead of 3 for A73. ARM looked at increasing the number of entries in the issue queues too, but it found this increased power more than performance, so it nixed the idea. Instead it added a dedicated NEON/FP store pipe with its own issue queue. The latency of a FP multiply-accumulate (MAC) has also been reduced to 5 cycles compared to 6 cycles on A73.

I’ll discuss the execution pipelines in greater detail as we work our way through the data path, but let’s start on the instruction side first. The A75 is still a “slot-based microarchitecture,” which was first introduced with the A73. ARM is not disclosing any additional details beyond its basic explanation from last year, namely that there are 8 “slots” that work to eliminate redundant access to resources within the instruction block, which ultimately reduces power consumption.
Both the A73 and A75 have a very simple instruction prefetcher that feeds into a fixed 64KB L1 I-cache that is 4-way set associative and uses a VIPT (Virtually Indexed, Physically Tagged) access scheme, common for L1 caches because of their sensitivity to latency.
The A73 received a completely new main branch predictor, along with a new 64-entry micro-BTAC for accelerating predictions. In addition to the main predictor, there’s also a static branch predictor, which is used as a fallback when the main predictor has insufficient history, and a return stack, which contains nested subroutine return addresses. An indirect predictor, which is only used when necessary (reducing its power penalty because indirect branches occur less frequently), uses a 2-way 256-entry BTAC (Branch Target Address Cache).
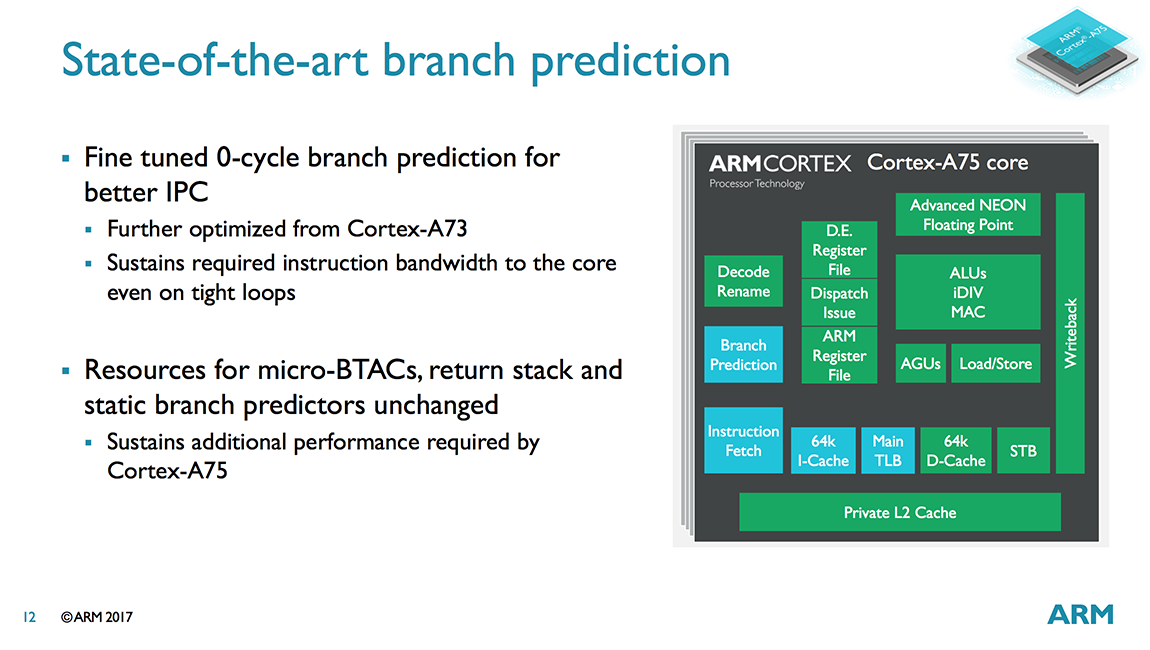
While designing the A75, ARM found that the A73’s branch predictor still performed well and that improving performance further resulted in diminishing returns, with power climbing faster than performance; therefore, the A73’s predictor was carried over to the A75. ARM did fine tune the 0-cycle micro-predictors, which sit upstream of the main predictor, improving IPC by further reducing the likelihood of pipeline bubbles in tight loops.
As I mentioned above, the A75 moves to a 3-wide instruction decode stage, up from 2-wide for the A73 and matching the 3-wide A72. ARM is always looking for ways to improve IPC (Instructions Per Cycle), and it noted that while running SPECint 2006 the A73 achieves an IPC of roughly 1.2 overall, increasing to 1.6 to 1.8 at specific sections within the test and dipping to 0.4 to 0.6 in others. Even much larger CPUs achieve an average IPC of just over 2. This does not mean you only need a 2-wide decoder, however, because there are situations that require greater throughput. For example, after a branch mispredict that requires a pipeline flush—which may occur 2-4 times for every 1000 instructions—the CPU needs to refill the issue queues as fast as possible so it can begin extracting ILP. So going wider helps throughput when you need a sudden burst of instructions. There’s a power and area penalty for going wider of course, because it causes a ripple effect through the rest of the pipeline, but it was clear to ARM that moving to 3-way superscalar was necessary to meet its IPC goals.
The A75’s Rename and Dispatch stages are similar to the A73’s. Like the A73 and other Sophia CPUs, there’s no reorder buffer or architectural register file in the A75. Instead it uses a physical register file for storing µop operands, reducing power by limiting the amount of data moving around the CPU and eliminating some instruction window bottlenecks that arise from using a reorder buffer.
The A75 does see some optimizations here, including the ability for loads to bypass writes, improving the core’s ability to execute out of order and better cope with an L2 cache miss. ARM also found that certain instructions that get cracked during the decode stage (because they need access to the register file during rename) were using too many entries in the A73’s issue queues, so the A75 now recombines these back into a single instruction after the rename stage, freeing up space in the issue queues for other µops.
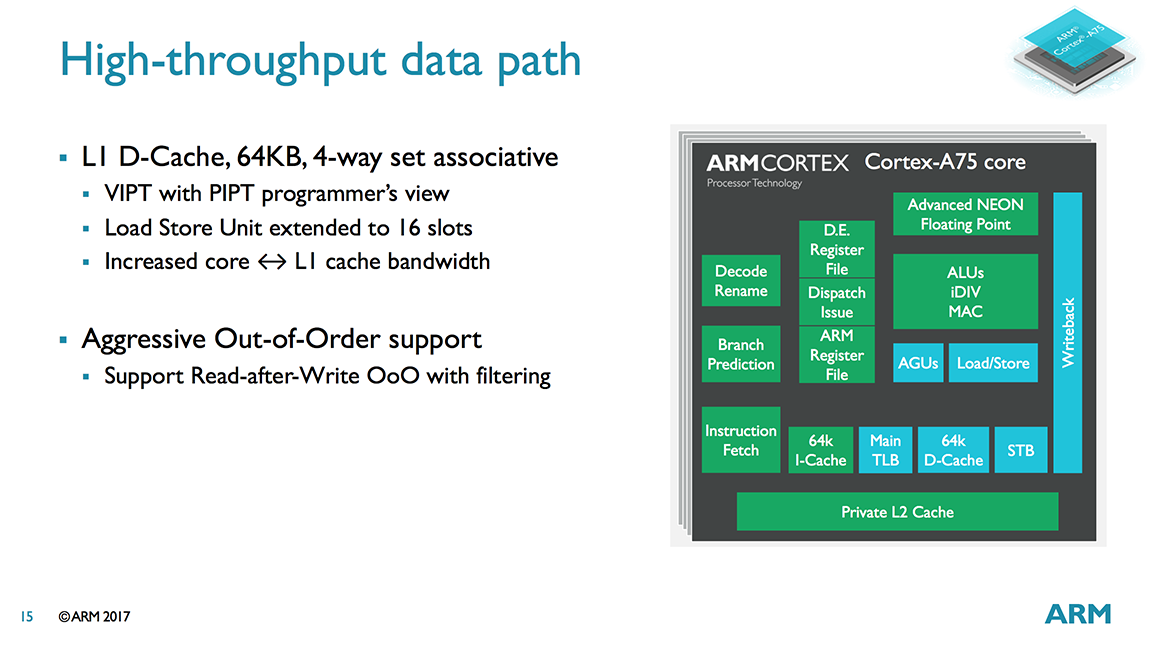
Moving over to the data path, we find an improved data prefetcher. The L1 and L2 prefetchers were already overhauled for A73, but the stride prefetcher has been retuned to better handle out of order execution for A75.
The 64KB L1 D-cache carries over nearly unchanged from A73. This is VIPT like the L1 I-cache, which reduces latency by performing the cache index lookup in parallel with the TLB translation. The A73/A75 handle aliasing issues, where several virtual addresses might reference the same physical address, in hardware, making the 4-way set associative VIPT cache look like a PIPT 8-way 32kB or 16-way 64KB cache to the programmer.
The A75 gets an integrated L2 cache that operates at core speed, reducing latency by more than 50% compared to the A73 that shares an L2 cache with the other CPUs in the same cluster. For instruction fetch, latency drops from 20-25 cycles to 11 cycles (10 cycle for a L1 miss, L2 hit), and for the lowest latency scenario (a load that forwards to the AGU because of a dependent load address) latency drops from 19 cycles to 8 cycles.
The optional L2 cache can be either 256KB or 512KB. Choosing the 512KB option only improves performance by about 2% compared to 256KB for a single core, but provides a better 4-5% uplift when using 4 A75 cores with DynamIQ. The L1 D-cache and L2 are now fully-exclusive instead of pseudo-exclusive like A73, which saves area because data is not duplicated in the L2 cache. The L1 I-cache is pseudo-inclusive.

ARM improved the overall L2 hit rate by biasing the L2 cache replacement policy to have a higher affinity for instructions. The L2’s higher hit rate and lower latency improves performance but also saves power and area by allowing the A75 to continue using a very simple instruction prefetcher.
The A75’s main TLB is now non-blocking with a two outstanding fetch capability including hit under miss (the A73 main TLB is a blocking design). This change improves performance when there’s a TLB miss requiring a page table walk in main system memory. With a non-blocking TLB, it can continue to process translation requests while waiting for the page table walk to complete, which takes a comparatively long time because it requires multiple memory accesses.
Our trip through the data side of the A75’s memory system ends with the AGUs (Address Generation Units). Another carry over from the A73, the two AGUs are capable of performing both loads and stores, offering greater flexibility and a higher issue rate into the memory system. The size of the store buffer (STB), where all stores are pushed once they’ve been committed and are no longer speculative, increases to 7 128-bit slots.

Now it’s time to shift our focus to the execution pipelines. The A75’s ALU/INT pipes are the same as A73. Both ALUs can perform basic operations such as additions and shifts, but only one ALU handles integer multiplication and multiply-accumulate operations, while the other focuses on integer division with a Radix-16 divider. This means the A73/A75 cannot perform two integer multiplies or divides in parallel, but it can dual issue a MUL/MAC alongside a divide/add/shift. While nearly all instructions complete in 1 or 2 cycles, more complex integer multiplication and division operations require additional cycles. It’s interesting that after making the move to 3-wide decode, ARM considered adding a third ALU/INT pipe; however, the performance increase was not enough to justify the increase in power.
The 2 64-bit NEON/Floating Point pipes have their own dedicated Rename stage and 128-bit register file, with each SIMD NEON pipe in the A73/A75 capable of performing 8 8-bit integer, 4 16-bit integer, 2 32-bit integer or single-precision floating-point (FP), or 1 64-bit integer or double-precision FP operations per cycle, giving programmers the flexibility to choose the right balance between precision and performance.
The A75 also gains native support for half-precision FP16 operations by updating to the ARMv8.2 architecture. Using less precise data types (16-bits for FP16 versus 32- or 64-bits) reduces the amount of memory/cache required to store data and improves memory bandwidth, which can be a desirable trade-off for certain applications like machine learning and image processing. The A73 and earlier big cores could fetch FP16 values, but they need to be converted to FP32 before execution, resulting in some additional overhead.
Looking to improve performance, many neural-network algorithms are dropping down to 8-bit precision, especially after training is complete. To speed up these algorithms, the A75 (courtesy of the ARMv8.2 architecture) includes a new INT8 dot product instruction, which combines multiple instructions that required being executed back to back to back into a single instruction, significantly improving latency.

Starting with the A73 microarchitecture, ARM worked to improve IPC by moving to 3-wide decode and improving the core’s out-of-order capability, while DynamIQ support means a higher performing integrated L2 cache backed by a new L3 cache. The ARMv8.2 architecture also provides new features and new NEON instructions for accelerating neural networks and image processing.








104 Comments
View All Comments
Meteor2 - Monday, May 29, 2017 - link
How?Paul A. Clayton - Monday, May 29, 2017 - link
The A55 design is constrained not merely by area and power but also by configurability. Being able to vary the L1 cache sizes from 16 KiB to 64 KiB means that the pipeline structure and cycle time is not optimized for one size. Targeting multiple processes and design factors (e.g., SRAM libraries can be tuned for different performance/area/power tradeoffs) also constrains optimization.While ARM might have had in mind a particular implementation for optimization (for which it might provide hard cores), it is still limited to providing acceptable designs for other implementations. Some microarchitectural optimizations might strongly depend on implementation details which are outside of ARM's control.
There are probably also higher-risk design possibilities that were not explored simply because the resources were not available. Having multiple design teams with similar targets typically would mean wasting effort, but such provides a potential for a better design. It would be difficult for ARM to charge for the cost of unused designs given that other designs are available.
Targeting a broad range of workloads also means a design will tend to be worse than a design targeting a narrower range of workloads.
Kevin G - Monday, May 29, 2017 - link
Of course they could but would those changes have permitted it still be within the design constraints of the A55? Small die size and lower power are two characteristics that are not compromised for the A55. Faster is easy to do with more power but considering that the A55 is the little core, higher power consumption is to be avoided. Similarly a faster core might be done with a larger die area. There are trade offs here but the pressure from ARM's customers is to keep this as small as possible.Considering those constraints, I considering any improvements to be rather impressive. If there is a silver bullet that ARM could have used to make it faster/smaller/consumer less power in these designs without violating the constraints they have in place, I'd like know what it was.
tipoo - Monday, May 29, 2017 - link
Alas, still waiting to find out how different Apples Zephyr is from standard Little cores like it. It's nearly twice as big.jjj - Monday, May 29, 2017 - link
"What will be the goal for the next core, which will be coming from ARM’s Austin team that produced the A72? "That was my main question too but my hope was that the next core is aiming for much higher IPC. They need it for server and dual big core configs in mobile on 7nm.
Or maybe they don't quite need it really, A75 is really fast and if the next core adds 15-20% higher IPC combined with higher clocks enabled by the process, that's quite a lot and rather amazing from a perf density perspective.
Not much talk about area, any clue how A75 + DynamIQ compare to previous solutions - ofc the cache part is easy to factor in.
It is interesting that A75 scales better with higher clocks, any guesses for clocks at 2W? A laptop with 4b4L would be rather nice.
A55 not targeting higher clocks seems a bit odd, would mean that power goes down if folks move from A53 on 16FF to A55 on 7nm so maybe ARM has another update before 7nm.
Meteor2 - Monday, May 29, 2017 - link
I think these are still mobile CPUs. It's up to Cavium et al to do ARM ISA-compatible designs for servers. ARM's not that bothered; the mobile market is far larger.jjj - Monday, May 29, 2017 - link
ARM is very eager to go server and just a year ago ARM was targeting 25% share in server by 2020. This gen does highlight infrastructure as they call it, a large segment where they've been gaining share and the next step is server.7nm is where it starts really, TSMC has the HPC version of the process and ARM needs to be ready too with the core that follows A75.
What's is unclear is the strategy. A75 is already desktop class so they could just increase IPC some more but maybe they can aim higher. It seems that the Austin team got an extra year to work on the next core so that's 3 years, could be an entirely new design.
Kevin G - Monday, May 29, 2017 - link
ARM in the server space is sound much like the hype of Linux on the desktop: always 'next year'.The challenges ARM designs have had have been to simply get out to market. AMD's Seattle chip is indeed out but suffered two years of delays and most of the design wins have evaporated due to it. AMD's K12 efforts are MIA right now. Similarly Cavium's ThunderX line is interesting but not the game changer it was hyped to be. Broadcom has exited the ARM server market after promoting an interesting design (SMT on ARM!). Applied Micro's efforts for ARM servers have been lost to corporate mergers. Caldexa folded years ago.
The one interesting ray of hope is that there are indeed some customers like Microsoft, Facebook, Google and Amazon who are interesting in ARM's low power nature to certain workloads. Microsoft has a version of Windows Server running on ARM but is not releasing it publicly, rather keeping it tied to their Azure cloud services. I have yet to hear where MS has gotten their ARM hardware from though. Google has dipped their toe into chip development for their deep learning efforts and it would be a straight forward process to piece together their own server designs from licensed IP blocks now that they have the in-house expertise to do it (saying they can and them doing it are two different things). In the end, the big cloud providers who could have spurred the ARM server space for everyone may keep the ARM server idea private to themselves while the rest of the market gets to deal with x86. Considering that x86 is perceived as higher power and higher cost, this serves the cloud providers well as it give incentive for companies to migrate to their cloud solutions instead of looking at ARM alternatives.
The other difficulty for ARM in the market place right now is that Intel preemptively released their response: the Xeon D. Intel was doing a performance/watt play there and it paid for for the low end server market. In most cases, the Xeon D for a pure single socket server was a better choice than the Xeon E5 1xxxx or Xeon E3 line up. I suspect that Intel management sees Xeon D as 'too good' and thus hasn't been quick to bring an updated Sky Lake version to market.
Wilco1 - Monday, May 29, 2017 - link
Please read: http://www.anandtech.com/show/11189/appliedmicro-x... - it says both Vulcan and XGene are alive. You forgot to mention QC's Centric (48 cores on 10nm, available this year). There are also 64-core/256GB DRAM beasts made by HiSilicon.jjj - Monday, May 29, 2017 - link
If you assume a 15-20% IPC gain over A75 for ARM's 7nm core and clock it past 4GHz for server, that's somewhat the worst case scenario for where ARM is in server in 2018-2019. We can assume DinamIQ evolves a bit by then too.That wouldn't be bad at all and ARM has extraordinary perf density. They might deliver more than that, we'll see.